
Sign Up
What is best time for the call?

Prompt caching has moved from a niche optimization to a core pillar of enterprise LLM operations. By 2026, enterprises using prompt caching reported an average 27% reduction in inference costs and up to 34% lower latency for high frequency use cases, according to Gartner 2026 and IDC 2026. For CIOs, IT leaders, and AI platform owners, prompt caching is now central to any serious LLM strategy.
This guide explains what prompt caching is, why it matters, and how to design a secure, scalable enterprise prompt cache that improves LLM inference speed, reduces token costs, and meets governance requirements.
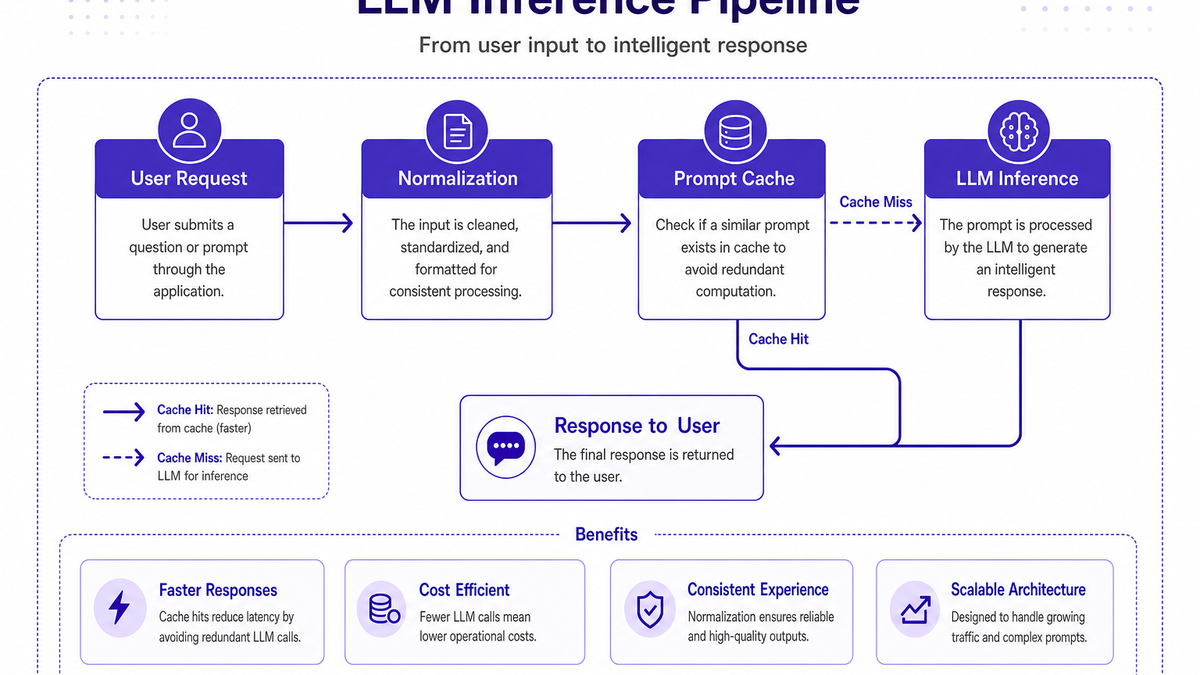
Prompt caching is the process of storing the inputs and outputs of LLM calls so that repeated or similar requests can reuse earlier responses instead of triggering a new, full cost inference.
In practice, an LLM cache stores a mapping between:
A normalized representation of a prompt or prompt + context
The model response (plus metadata such as tokens used, latency, and policy flags)
When a new request arrives, the LLM cache layer checks for a match. If found, it returns the cached response instantly, avoiding additional tokens and reducing LLM operational cost.
Recent research underscores its impact:
Enterprises using prompt caching report average cache hit rates of 57% in production LLM deployments (Forrester 2026).
Cache optimized LLM infrastructure has seen 2.4x improvement in API throughput in multi tenant scenarios (Gartner 2026).
Global token savings from advanced large language model cache strategies could surpass $4.3B by 2026 (McKinsey 2026).
As Dr. Rashmi Sinha, AI systems architect at a leading research group, notes, "Prompt caching is fast becoming a critical lever in reducing both operational cost and latency for enterprise grade LLM deployments, especially as organizations scale beyond hundreds of concurrent users" (Forrester 2026).
At scale, most enterprise AI workflows exhibit a high degree of repetition: recurring queries, templated prompts, similar tickets, and repeated knowledge base lookups. A well designed enterprise prompt cache exploits this redundancy to reduce LLM redundancy reduction.
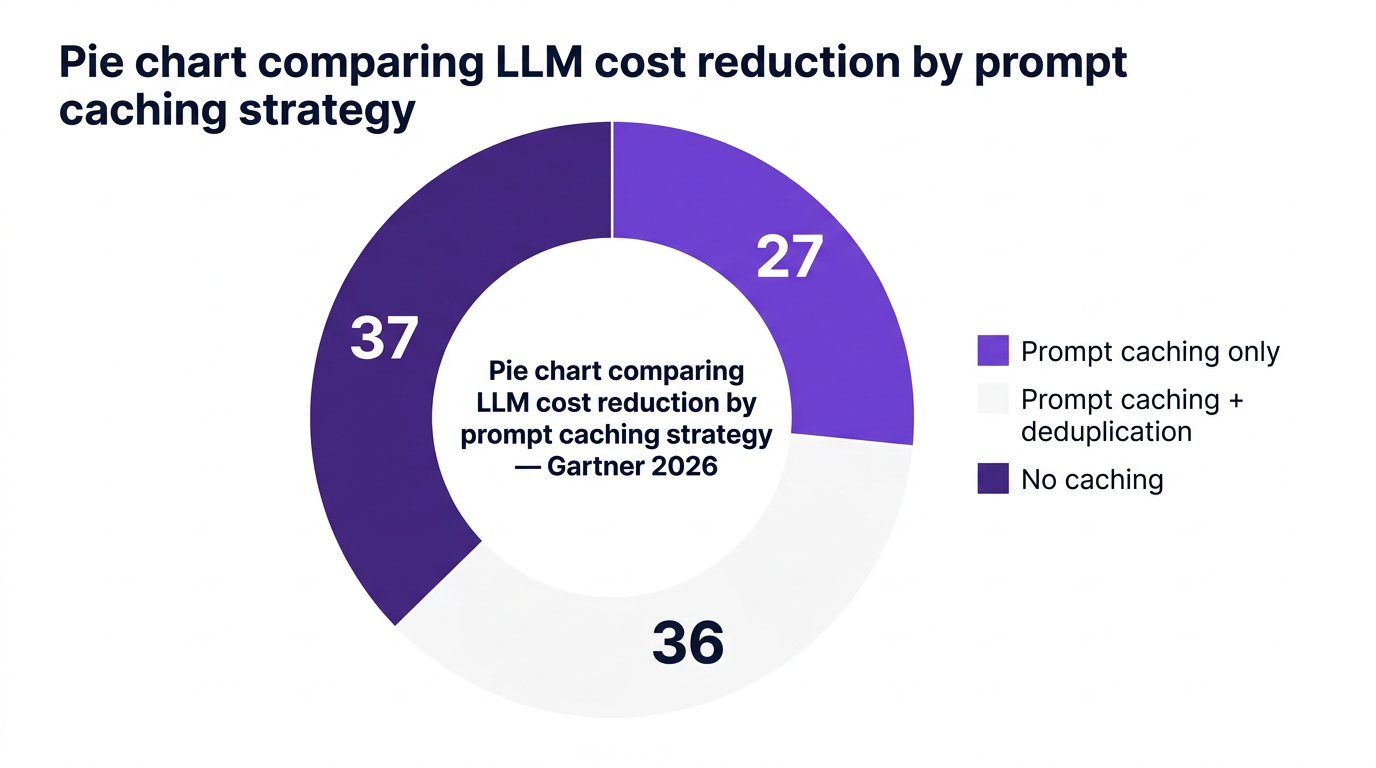
According to Gartner 2026, organizations that combine prompt caching only see about 27% cost reduction, while those combining prompt caching with deduplication and optimization patterns reach 36% savings.
Token cost optimization
Repeated prompts reuse existing outputs, driving AI token optimization across support bots, copilots, and internal tools. High frequency prompts, such as policy lookups or standard explanations, become almost free after the first call.
Improved LLM inference speed
IDC 2026 found that prompt caching reduced LLM latency by up to 34% in high volume scenarios. Faster responses mean better user experience for chatbots, agents, and developer copilots.
Higher throughput and API resilience
Cache hits eliminate round trips to external APIs, improving resiliency against rate limits and model provider outages. Gartner 2026 reports 2.4x API throughput improvement for cache optimized multi tenant LLM infrastructures.
SaaS AI cost savings at portfolio scale
When LLM usage is distributed across many SaaS tools, a shared prompt cache layer becomes a key source of SaaS AI cost savings and central reporting.
A useful analogy for executives: think of prompt caching as an L3 cache for your entire AI stack. Just as CPU caches eliminate repeated trips to main memory, an LLM cache reduces trips to expensive inference endpoints.
Prompt caching for a hobby project is trivial. Prompt caching for enterprise LLM operations is not.
It has to consider multi tenant access, strict compliance boundaries, and AI workflow governance. Below is a reference architecture tailored for large organizations.

Request normalization layer
Canonicalizes prompts by stripping volatile data (timestamps, IDs) while retaining semantic content. Enables AI prompt deduplication so that semantically equivalent prompts map to a single key.
Prompt cache implementation
Stores prompt signatures and responses with metadata such as:
User or tenant ID
Data classification label
Model version
Time to live (TTL)
Cache policy (shared, private, or restricted)
Governance and policy engine
Evaluates whether a prompt is cacheable based on content, sensitivity, and compliance rules. Enforces masking, anonymization, or “no cache” decisions for specific data types to support secure prompt caching.
Analytics and observability
Tracks cache hit rate LLM metrics by app, team, and region. Surfaces which workflows drive the most LLM operational cost and where AI prompt caching strategies are underperforming.
Integration with SaaS and internal systems
Integrates across AI powered SaaS, internal applications, and platforms, ensuring a unified multi tenant LLM caching strategy.
Cache keys are central to context window efficiency:
Too narrow and you miss reuse opportunities.
Too broad and you risk serving stale or incorrect outputs for specific users.
Common patterns:
Strict key: full prompt text plus system instructions and model version.
Normalized key: semantic fingerprint plus role and use case.
Hybrid key: strict matching for sensitive flows and normalized for low risk, high volume flows.
The right approach varies by use case, which is why governance and observability are critical.
As Priya Deshmukh, a cloud security analyst at a leading advisory firm, warns, "Governance and security must be at the forefront when designing enterprise prompt caches, ensuring sensitive context is not inadvertently exposed during cache hits" (Deloitte 2026).
80% of enterprises that prioritized secure prompt caching reported improved compliance with internal and regulatory controls by 2026 (Deloitte 2026). That improvement came from treating the cache as part of the secure inference pipeline, not as a bolt on optimization.
To align with AI workflow governance and enterprise AI adoption standards, your design should:
Classify prompts and responses by sensitivity
Public, internal, confidential, regulated. Lower sensitivity prompts are cacheable across tenants, higher sensitivity may be user or team scoped only.
Apply role based and tenant based scoping
Multi tenant LLM caching must guarantee that cached responses created in one tenant cannot be surfaced in another, unless explicitly authorized. For regulated industries, restrict cross tenant cache reuse entirely.
Log everything for auditability
Every cache hit or miss should be logged with: who, what, when, where, and why. Governance focused prompt cache solutions with detailed audit trails saw a 60% increase in adoption among large enterprises in 2026 (Deloitte 2026).
Encryption at rest and in transit for all cached data.
Fine grained access control at the cache layer, aligned with existing identity systems.
Data minimization: avoid caching PII or highly regulated data unless strongly justified.
Configurable TTLs and cache eviction policy tuned to risk category and use case.
When these controls fail or are missing, prompt caching can become a shadow data store that drifts away from your primary security posture. That is the primary failure mode CIOs should guard against.
Explore how CloudNuro streamlines AI cost and governance with a tailored tour. Request a Demo
Implementing scalable prompt caching begins with clear objectives: reduce LLM operational cost, improve latency, and preserve compliance. The following phased approach works well for most enterprises.
Start where LLM inference speed and cost matter most:
Customer support assistants
Knowledge search and summarization
Code review and documentation copilots
Policy, HR, and compliance assistants
For each, estimate:
Current token spend and call volume
Latency sensitivity
Data classification profile
Define your prompt caching design along four axes:
Scope: global cache, per app, per tenant, or hybrid.
Key strategy: strict, normalized, or hybrid.
TTL and eviction: align your cache eviction policy with accuracy and freshness requirements.
Privacy rules: what is cacheable, masked, or blocked.
Introduce AI prompt deduplication at this stage, using fingerprints to cluster similar prompts and limit cache blowup.
Track:
Cache hit rate by application and user segment.
Latency distributions for cache hits versus misses.
Token savings attributable to caching.
Forrester 2026 reports that production deployments reach 57% average cache hit rate, with top performers surpassing 60%. Use these figures as reference points.
Then, iteratively tune:
TTL per route or use case.
Normalization strategies.
Deduplication thresholds.
Once a basic cache is functioning, advanced teams introduce predictive prompt caching using historical patterns to pre warm the cache:
Analyze repeated sequences and time of day patterns.
Pre generate answers for anticipated prompts before users ask.
Gartner 2026 identifies predictive caching as a top trend for maximizing cache efficiency and token reuse strategies.
Prompt caching is both an infrastructure decision and a financial one. Align with FinOps and operations teams to:
Tie cache metrics to AI cost optimization KPIs.
Co own policies that impact spend and performance.
Integrate metrics into broader FinOps services dashboards.
This is also where SaaS AI cost savings become visible to CFOs and business owners.
A global manufacturer introduced a unified large language model cache across its internal knowledge assistant and supplier helpdesk.
Within six months:
Token usage fell by 32%, cutting annual inference costs by over $1M (IDC 2026 analysis).
Cache hit rates stabilized above 60% for repetitive supplier queries.
Average response time dropped by nearly a third, improving user satisfaction for both internal and external stakeholders.
Similarly, a global payments provider implemented secure, role based prompt caching enterprise patterns in its fraud investigation workflows.
By aligning caching with strict access controls and data residency rules, it reported:
29% drop in model latency for investigators.
Measurable improvements in audit readiness and compliance posture (Deloitte 2026).
These outcomes illustrate a key insight: prompt caching only delivers durable value when tightly integrated with governance, security, and financial accountability.
CloudNuro is designed for enterprises that treat LLMs as first class infrastructure. Its AI Custodian and Unified Cloud Custodian capabilities extend core SaaS management strengths into the AI domain, including prompt caching.
Key ways CloudNuro helps you operationalize an enterprise prompt cache:
Automated cache aware discovery and observability
CloudNuro maps where LLM calls occur across your SaaS and internal estate, through SaaS management and IT operations solutions. It correlates prompt patterns, token spend, and cache hit rate LLM metrics across apps.
Policy driven, secure prompt caching
Using CloudNuro AI Custodian, teams can define cacheability rules based on sensitivity, use case, and tenant. Granular policies govern what is cached, who can reuse responses, and how multi tenant LLM caching behaves across business units.
Unified cost governance and chargeback
With CloudNuro Chargeback and FinOps services, enterprises can allocate LLM operational cost and token usage to departments, projects, or regions. This makes token cost optimization from prompt caching highly visible and actionable for both IT and Finance leaders.
Analytics on LLM redundancy reduction and optimization
Embedded analytics highlight high redundancy flows where AI token optimization potential is highest. Leaders can prioritize AI prompt caching strategies where the ROI is clearest.
If you are evaluating how to scale AI usage while maintaining control, CloudNuro provides the governance first foundation for secure prompt caching, workload visibility, and SaaS AI cost savings.
Get a free assessment of your LLM token spend, caching opportunities, and AI governance posture with CloudNuro's experts. Get a free assessment
Prompt caching is a technique where enterprises store LLM prompts and responses so that repeated or similar requests can reuse prior outputs instead of calling the model again.
This improves LLM inference speed, reduces token usage, and cuts LLM operational cost on high volume workloads.
By reusing responses for repeat prompts, prompt caching avoids re paying for the same computation. Gartner 2026 reports 27% average cost reduction from prompt caching alone, and up to 36% when combined with deduplication strategies.
These savings compound as AI adoption grows across multiple SaaS tools and internal applications.
The most important drivers of cache hit rate LLM are:
The level of repetition in your workflows.
How prompts are normalized and keyed.
TTLs and eviction policies.
Breadth of adoption across your AI estate.
Predictive caching and token reuse strategies can further improve hit rates beyond baseline implementations.
Treat the prompt cache as part of your secure inference pipeline and apply the same policies you use for production data stores:
Classify content and apply role based access controls.
Block caching for sensitive or regulated payloads.
Enforce encryption and detailed audit logging.
Research from Deloitte 2026 shows that 80% of enterprises prioritizing secure prompt caching reported better compliance outcomes.
Yes, but multi tenant LLM caching must be designed carefully. Cache entries should be scoped to the correct tenant or line of business, and cross tenant reuse should be opt in and policy controlled.
Enterprises in regulated sectors often restrict reuse to within a single tenant or domain to avoid accidental data exposure.
Prompt caching is less effective when:
Prompts are highly unique or one off.
Context changes rapidly and responses become stale quickly.
Strict privacy rules block caching for most workflows.
Even in these cases, targeted caching for lower risk, repetitive flows can still deliver meaningful SaaS AI cost savings.
Prompt caching is no longer a niche optimization. It is a foundational capability for any enterprise aiming to scale LLM usage responsibly.
Used well, prompt caching can:
Improve LLM inference speed for business critical workflows.
Deliver double digit LLM cost reduction through AI token optimization.
Strengthen AI workflow governance by making prompt reuse auditable and controlled.
As Miguel Estrada, VP of AI platform engineering at a leading research firm, summarizes, "As LLM usage scales in enterprise SaaS, prompt reuse, deduplication, and secure multi tenant caching strategies are now foundational for achieving sustainable AI driven efficiency savings" (Gartner 2026).
Experience the CloudNuro difference with a personalized demo. Request a Demo
CloudNuro is a leader in Enterprise SaaS Management Platforms, providing enterprises with unmatched visibility, governance, and cost optimization. Recognized twice in a row in the SaaS Management Platforms category and named a Leader in the SoftwareReviews Data Quadrant, CloudNuro is trusted by global enterprises and government agencies to bring financial discipline to SaaS, cloud, and AI.
Trusted by enterprises such as Konica Minolta and Federal Signal, CloudNuro provides centralized SaaS inventory, license optimization, and renewal management along with advanced cost allocation and chargeback, giving IT and Finance leaders the visibility, control, and cost conscious culture needed to drive financial discipline.
Request a Demo | Get Free Savings | Explore Product
Request a Demo -> https://www.cloudnuro.ai/request-demo
Get Free Savings -> https://www.cloudnuro.ai/free-savings-assessment
Explore Product -> https://www.cloudnuro.ai/product-overview
Request a no cost, no obligation free assessment —just 15 minutes to savings!
Get StartedPrompt caching has moved from a niche optimization to a core pillar of enterprise LLM operations. By 2026, enterprises using prompt caching reported an average 27% reduction in inference costs and up to 34% lower latency for high frequency use cases, according to Gartner 2026 and IDC 2026. For CIOs, IT leaders, and AI platform owners, prompt caching is now central to any serious LLM strategy.
This guide explains what prompt caching is, why it matters, and how to design a secure, scalable enterprise prompt cache that improves LLM inference speed, reduces token costs, and meets governance requirements.
Prompt caching is the process of storing the inputs and outputs of LLM calls so that repeated or similar requests can reuse earlier responses instead of triggering a new, full cost inference.
In practice, an LLM cache stores a mapping between:
A normalized representation of a prompt or prompt + context
The model response (plus metadata such as tokens used, latency, and policy flags)
When a new request arrives, the LLM cache layer checks for a match. If found, it returns the cached response instantly, avoiding additional tokens and reducing LLM operational cost.
Recent research underscores its impact:
Enterprises using prompt caching report average cache hit rates of 57% in production LLM deployments (Forrester 2026).
Cache optimized LLM infrastructure has seen 2.4x improvement in API throughput in multi tenant scenarios (Gartner 2026).
Global token savings from advanced large language model cache strategies could surpass $4.3B by 2026 (McKinsey 2026).
As Dr. Rashmi Sinha, AI systems architect at a leading research group, notes, "Prompt caching is fast becoming a critical lever in reducing both operational cost and latency for enterprise grade LLM deployments, especially as organizations scale beyond hundreds of concurrent users" (Forrester 2026).
At scale, most enterprise AI workflows exhibit a high degree of repetition: recurring queries, templated prompts, similar tickets, and repeated knowledge base lookups. A well designed enterprise prompt cache exploits this redundancy to reduce LLM redundancy reduction.
According to Gartner 2026, organizations that combine prompt caching only see about 27% cost reduction, while those combining prompt caching with deduplication and optimization patterns reach 36% savings.
Token cost optimization
Repeated prompts reuse existing outputs, driving AI token optimization across support bots, copilots, and internal tools. High frequency prompts, such as policy lookups or standard explanations, become almost free after the first call.
Improved LLM inference speed
IDC 2026 found that prompt caching reduced LLM latency by up to 34% in high volume scenarios. Faster responses mean better user experience for chatbots, agents, and developer copilots.
Higher throughput and API resilience
Cache hits eliminate round trips to external APIs, improving resiliency against rate limits and model provider outages. Gartner 2026 reports 2.4x API throughput improvement for cache optimized multi tenant LLM infrastructures.
SaaS AI cost savings at portfolio scale
When LLM usage is distributed across many SaaS tools, a shared prompt cache layer becomes a key source of SaaS AI cost savings and central reporting.
A useful analogy for executives: think of prompt caching as an L3 cache for your entire AI stack. Just as CPU caches eliminate repeated trips to main memory, an LLM cache reduces trips to expensive inference endpoints.
Prompt caching for a hobby project is trivial. Prompt caching for enterprise LLM operations is not.
It has to consider multi tenant access, strict compliance boundaries, and AI workflow governance. Below is a reference architecture tailored for large organizations.
Request normalization layer
Canonicalizes prompts by stripping volatile data (timestamps, IDs) while retaining semantic content. Enables AI prompt deduplication so that semantically equivalent prompts map to a single key.
Prompt cache implementation
Stores prompt signatures and responses with metadata such as:
User or tenant ID
Data classification label
Model version
Time to live (TTL)
Cache policy (shared, private, or restricted)
Governance and policy engine
Evaluates whether a prompt is cacheable based on content, sensitivity, and compliance rules. Enforces masking, anonymization, or “no cache” decisions for specific data types to support secure prompt caching.
Analytics and observability
Tracks cache hit rate LLM metrics by app, team, and region. Surfaces which workflows drive the most LLM operational cost and where AI prompt caching strategies are underperforming.
Integration with SaaS and internal systems
Integrates across AI powered SaaS, internal applications, and platforms, ensuring a unified multi tenant LLM caching strategy.
Cache keys are central to context window efficiency:
Too narrow and you miss reuse opportunities.
Too broad and you risk serving stale or incorrect outputs for specific users.
Common patterns:
Strict key: full prompt text plus system instructions and model version.
Normalized key: semantic fingerprint plus role and use case.
Hybrid key: strict matching for sensitive flows and normalized for low risk, high volume flows.
The right approach varies by use case, which is why governance and observability are critical.
As Priya Deshmukh, a cloud security analyst at a leading advisory firm, warns, "Governance and security must be at the forefront when designing enterprise prompt caches, ensuring sensitive context is not inadvertently exposed during cache hits" (Deloitte 2026).
80% of enterprises that prioritized secure prompt caching reported improved compliance with internal and regulatory controls by 2026 (Deloitte 2026). That improvement came from treating the cache as part of the secure inference pipeline, not as a bolt on optimization.
To align with AI workflow governance and enterprise AI adoption standards, your design should:
Classify prompts and responses by sensitivity
Public, internal, confidential, regulated. Lower sensitivity prompts are cacheable across tenants, higher sensitivity may be user or team scoped only.
Apply role based and tenant based scoping
Multi tenant LLM caching must guarantee that cached responses created in one tenant cannot be surfaced in another, unless explicitly authorized. For regulated industries, restrict cross tenant cache reuse entirely.
Log everything for auditability
Every cache hit or miss should be logged with: who, what, when, where, and why. Governance focused prompt cache solutions with detailed audit trails saw a 60% increase in adoption among large enterprises in 2026 (Deloitte 2026).
Encryption at rest and in transit for all cached data.
Fine grained access control at the cache layer, aligned with existing identity systems.
Data minimization: avoid caching PII or highly regulated data unless strongly justified.
Configurable TTLs and cache eviction policy tuned to risk category and use case.
When these controls fail or are missing, prompt caching can become a shadow data store that drifts away from your primary security posture. That is the primary failure mode CIOs should guard against.
Explore how CloudNuro streamlines AI cost and governance with a tailored tour. Request a Demo
Implementing scalable prompt caching begins with clear objectives: reduce LLM operational cost, improve latency, and preserve compliance. The following phased approach works well for most enterprises.
Start where LLM inference speed and cost matter most:
Customer support assistants
Knowledge search and summarization
Code review and documentation copilots
Policy, HR, and compliance assistants
For each, estimate:
Current token spend and call volume
Latency sensitivity
Data classification profile
Define your prompt caching design along four axes:
Scope: global cache, per app, per tenant, or hybrid.
Key strategy: strict, normalized, or hybrid.
TTL and eviction: align your cache eviction policy with accuracy and freshness requirements.
Privacy rules: what is cacheable, masked, or blocked.
Introduce AI prompt deduplication at this stage, using fingerprints to cluster similar prompts and limit cache blowup.
Track:
Cache hit rate by application and user segment.
Latency distributions for cache hits versus misses.
Token savings attributable to caching.
Forrester 2026 reports that production deployments reach 57% average cache hit rate, with top performers surpassing 60%. Use these figures as reference points.
Then, iteratively tune:
TTL per route or use case.
Normalization strategies.
Deduplication thresholds.
Once a basic cache is functioning, advanced teams introduce predictive prompt caching using historical patterns to pre warm the cache:
Analyze repeated sequences and time of day patterns.
Pre generate answers for anticipated prompts before users ask.
Gartner 2026 identifies predictive caching as a top trend for maximizing cache efficiency and token reuse strategies.
Prompt caching is both an infrastructure decision and a financial one. Align with FinOps and operations teams to:
Tie cache metrics to AI cost optimization KPIs.
Co own policies that impact spend and performance.
Integrate metrics into broader FinOps services dashboards.
This is also where SaaS AI cost savings become visible to CFOs and business owners.
A global manufacturer introduced a unified large language model cache across its internal knowledge assistant and supplier helpdesk.
Within six months:
Token usage fell by 32%, cutting annual inference costs by over $1M (IDC 2026 analysis).
Cache hit rates stabilized above 60% for repetitive supplier queries.
Average response time dropped by nearly a third, improving user satisfaction for both internal and external stakeholders.
Similarly, a global payments provider implemented secure, role based prompt caching enterprise patterns in its fraud investigation workflows.
By aligning caching with strict access controls and data residency rules, it reported:
29% drop in model latency for investigators.
Measurable improvements in audit readiness and compliance posture (Deloitte 2026).
These outcomes illustrate a key insight: prompt caching only delivers durable value when tightly integrated with governance, security, and financial accountability.
CloudNuro is designed for enterprises that treat LLMs as first class infrastructure. Its AI Custodian and Unified Cloud Custodian capabilities extend core SaaS management strengths into the AI domain, including prompt caching.
Key ways CloudNuro helps you operationalize an enterprise prompt cache:
Automated cache aware discovery and observability
CloudNuro maps where LLM calls occur across your SaaS and internal estate, through SaaS management and IT operations solutions. It correlates prompt patterns, token spend, and cache hit rate LLM metrics across apps.
Policy driven, secure prompt caching
Using CloudNuro AI Custodian, teams can define cacheability rules based on sensitivity, use case, and tenant. Granular policies govern what is cached, who can reuse responses, and how multi tenant LLM caching behaves across business units.
Unified cost governance and chargeback
With CloudNuro Chargeback and FinOps services, enterprises can allocate LLM operational cost and token usage to departments, projects, or regions. This makes token cost optimization from prompt caching highly visible and actionable for both IT and Finance leaders.
Analytics on LLM redundancy reduction and optimization
Embedded analytics highlight high redundancy flows where AI token optimization potential is highest. Leaders can prioritize AI prompt caching strategies where the ROI is clearest.
If you are evaluating how to scale AI usage while maintaining control, CloudNuro provides the governance first foundation for secure prompt caching, workload visibility, and SaaS AI cost savings.
Get a free assessment of your LLM token spend, caching opportunities, and AI governance posture with CloudNuro's experts. Get a free assessment
Prompt caching is a technique where enterprises store LLM prompts and responses so that repeated or similar requests can reuse prior outputs instead of calling the model again.
This improves LLM inference speed, reduces token usage, and cuts LLM operational cost on high volume workloads.
By reusing responses for repeat prompts, prompt caching avoids re paying for the same computation. Gartner 2026 reports 27% average cost reduction from prompt caching alone, and up to 36% when combined with deduplication strategies.
These savings compound as AI adoption grows across multiple SaaS tools and internal applications.
The most important drivers of cache hit rate LLM are:
The level of repetition in your workflows.
How prompts are normalized and keyed.
TTLs and eviction policies.
Breadth of adoption across your AI estate.
Predictive caching and token reuse strategies can further improve hit rates beyond baseline implementations.
Treat the prompt cache as part of your secure inference pipeline and apply the same policies you use for production data stores:
Classify content and apply role based access controls.
Block caching for sensitive or regulated payloads.
Enforce encryption and detailed audit logging.
Research from Deloitte 2026 shows that 80% of enterprises prioritizing secure prompt caching reported better compliance outcomes.
Yes, but multi tenant LLM caching must be designed carefully. Cache entries should be scoped to the correct tenant or line of business, and cross tenant reuse should be opt in and policy controlled.
Enterprises in regulated sectors often restrict reuse to within a single tenant or domain to avoid accidental data exposure.
Prompt caching is less effective when:
Prompts are highly unique or one off.
Context changes rapidly and responses become stale quickly.
Strict privacy rules block caching for most workflows.
Even in these cases, targeted caching for lower risk, repetitive flows can still deliver meaningful SaaS AI cost savings.
Prompt caching is no longer a niche optimization. It is a foundational capability for any enterprise aiming to scale LLM usage responsibly.
Used well, prompt caching can:
Improve LLM inference speed for business critical workflows.
Deliver double digit LLM cost reduction through AI token optimization.
Strengthen AI workflow governance by making prompt reuse auditable and controlled.
As Miguel Estrada, VP of AI platform engineering at a leading research firm, summarizes, "As LLM usage scales in enterprise SaaS, prompt reuse, deduplication, and secure multi tenant caching strategies are now foundational for achieving sustainable AI driven efficiency savings" (Gartner 2026).
Experience the CloudNuro difference with a personalized demo. Request a Demo
CloudNuro is a leader in Enterprise SaaS Management Platforms, providing enterprises with unmatched visibility, governance, and cost optimization. Recognized twice in a row in the SaaS Management Platforms category and named a Leader in the SoftwareReviews Data Quadrant, CloudNuro is trusted by global enterprises and government agencies to bring financial discipline to SaaS, cloud, and AI.
Trusted by enterprises such as Konica Minolta and Federal Signal, CloudNuro provides centralized SaaS inventory, license optimization, and renewal management along with advanced cost allocation and chargeback, giving IT and Finance leaders the visibility, control, and cost conscious culture needed to drive financial discipline.
Request a Demo | Get Free Savings | Explore Product
Request a Demo -> https://www.cloudnuro.ai/request-demo
Get Free Savings -> https://www.cloudnuro.ai/free-savings-assessment
Explore Product -> https://www.cloudnuro.ai/product-overview
Request a no cost, no obligation free assessment - just 15 minutes to savings!
Get StartedWe're offering complimentary ServiceNow license assessments to only 25 enterprises this quarter who want to unlock immediate savings without disrupting operations.
Get Free AssessmentGet Started



CloudNuro Corp
1755 Park St. Suite 207
Naperville, IL 60563
Phone : +1-630-277-9470
Email: info@cloudnuro.com





.webp)

Recognized Leader in SaaS Management Platforms by Info-Tech SoftwareReviews



