
Sign Up
What is best time for the call?

The integration of generative artificial intelligence creates significant infrastructure challenges for modern engineering teams. Artificial intelligence implementation routinely brings unpredictable monthly operational expenses. Compute-intensive requests continuously drain available financial resources. However, established engineering groups find reliable enterprise AI cost governance through optimized token logic. By structuring model requests efficiently, technology departments achieve substantive LLM cost reduction with caching.
When user queries hit a complex language model repeatedly, computing the identical output squanders expensive cloud allocations. Standardizing request storage permanently prevents this duplicate processing. This specific systematic approach bypasses redundant generation entirely. Implementing pure, architecture-agnostic logic provides consistent financial returns for advanced generative AI products. This technical guide details a vendor-neutral playbook designed specifically to establish durable memory layers and protect valuable AI budgets.
Running vast language models requires astronomical computational power across server clusters. Every single generated sentence consumes specific processing units within the hosting environment. As internal application usage scales among diverse employee groups, these incremental processing requests compound rapidly. Gartner research from 2026 reveals that 50% of top enterprise organizations cite AI workload cost optimization as their primary operational challenge during initial adoption phases. Unchecked token generation swiftly forces cloud budgets toward critical threshold warnings.
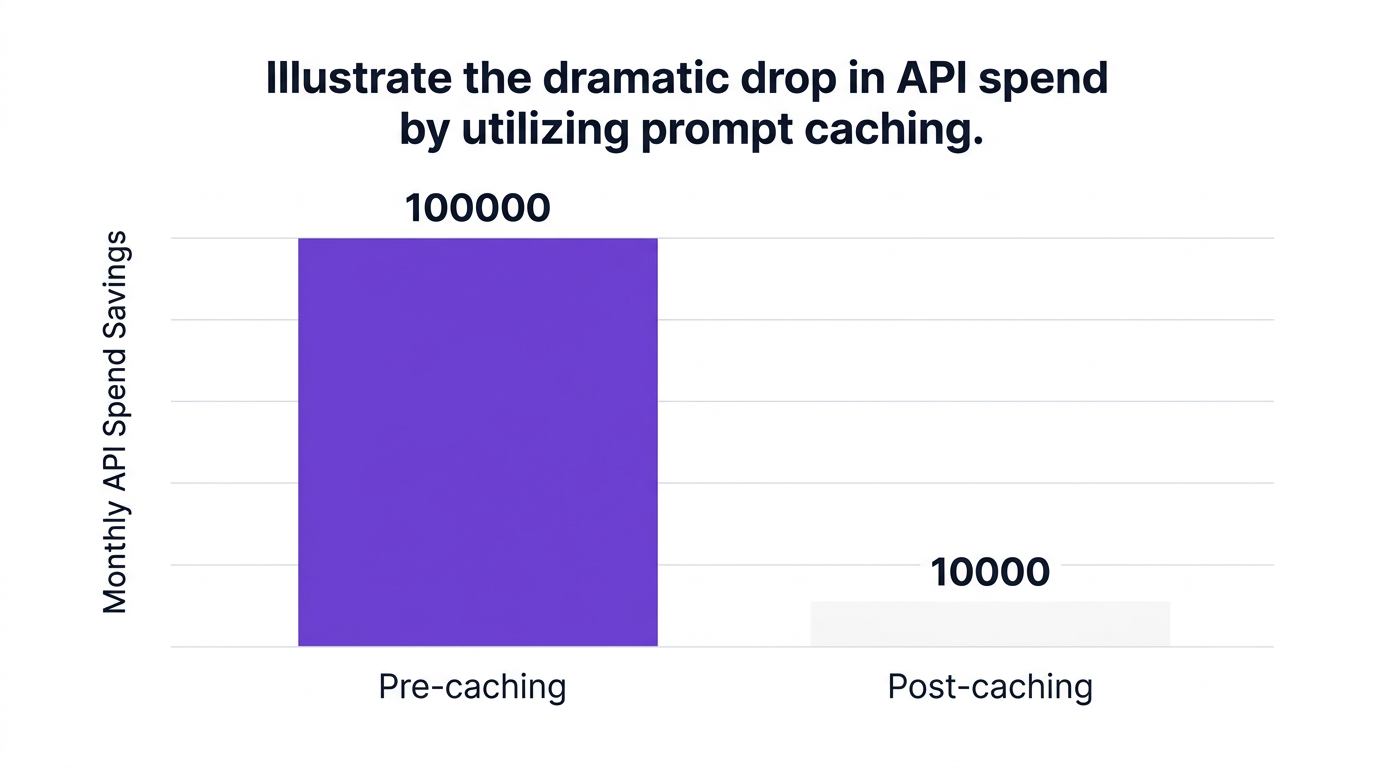
Unmanaged diagnostic and conversational API bills frequently escalate without sufficient warning. A 2026 cost optimization benchmark survey reported that deploying active prompt caching structures decreased average API expenditures from $100,000 per month to under $10,000 per month. Optimizing these intricate systems represents a massive step toward long-term corporate AI sustainability. A targeted generative AI cost control mechanism guarantees that artificial intelligence deployment remains distinctly profitable over extended operating periods.
Furthermore, elastic AI workload scaling creates fluctuating demand that complicates standard budget forecasting. Organizations require predictable recurring expenses to justify continued engineering investment. By analyzing precise tokenized AI billing statements, finance teams identify major discrepancies between projected usage and actual technical consumption. Addressing these exact discrepancies forms the foundation for reliable, resilient corporate infrastructure.
At its core, a caching architecture acts as an intelligent intermediary. It sits directly between the application user interface and the backend processing cluster. When a specific user input enters the active system, the custom memory layer checks historic reference logs for identical text matches. If an exact match exists, the technical architecture returns the stored result instantly.
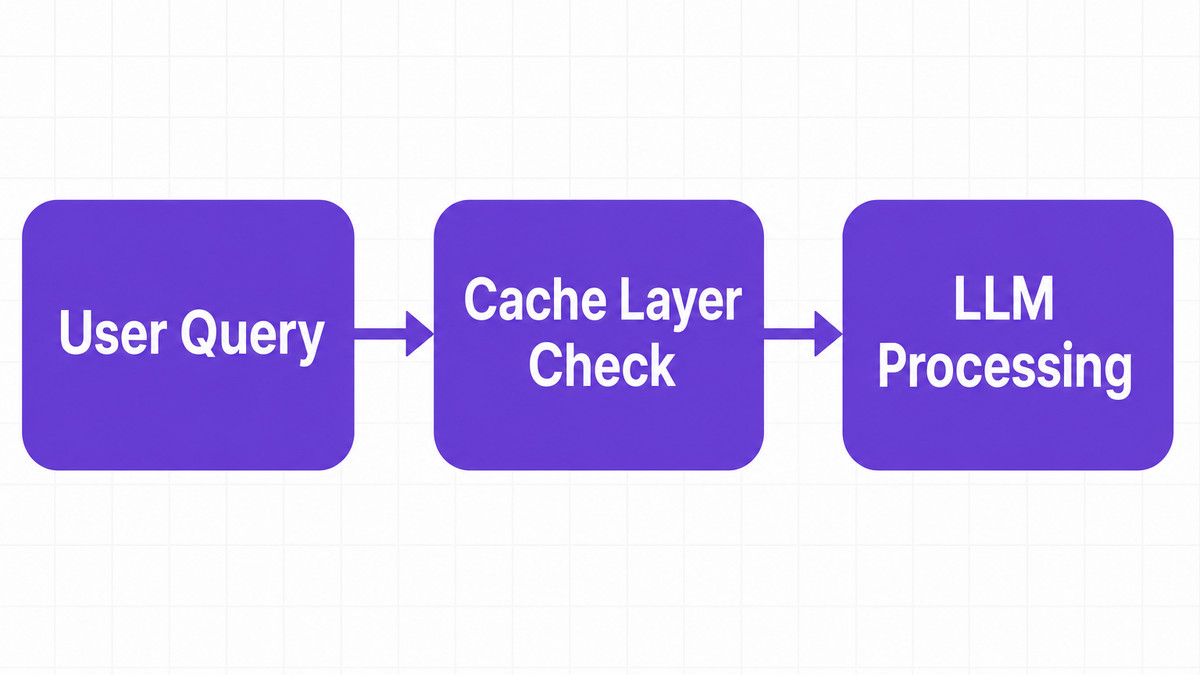
This operational framework moves processing from raw compute-bound workloads to highly memory-optimized retrievals. Rather than waiting for a complete machine learning generation cycle, responsive applications deliver archived answers. This sophisticated AI caching technique directly slashes expensive model serving expenses. Industry specialists emphasize that architecture-agnostic layers guarantee these savings across multiple hosting environments, preventing detrimental vendor dependencies completely.
Establishing these systems requires careful coordination among platform architects. Engineering leaders must configure exact caching rules that determine the appropriate lifespan for stored data points. Complex technical responses might require frequent refreshing, while standard operational definitions remain perfectly static. Mapping these specific parameters allows corporate teams to extract maximum value from existing server deployments. Continuous optimization of the caching architecture establishes a permanent efficiency standard.
Token optimization via deliberate prompt engineering provides a secondary, yet equally vital, financial advantage. When combined with intelligent caching protocols, streamlined engineering yields an additional 15% to 20% reduction in serving costs, according to a 2026 Forrester report. Organizations seeking immediate financial accountability rely heavily on deploying these dual mechanisms simultaneously.
Financial decision-makers require absolute evidence of cost-effective LLM solutions before authorizing widespread internal deployment. Establishing positive return on investment happens with surprising speed when the designated caching layer operates correctly. According to a 2026 IDC study, 45% of organizations implementing these architectures achieve mathematically positive returns within the first three months of active usage. Proper AI prompt efficiency planning clearly converts previously wasted cloud computing allocations into tangible working capital.
These rapid financial returns validate the initial engineering investment necessary for deployment. Companies capture the LLM vendor cost saving metrics immediately upon activation. By carefully auditing API transmission loads, managers construct precise financial summaries that document complete transformation progress. Eliminating wasteful token generation allows technical teams to fund other critical platform enhancements.
The true definitive measure of optimization success lies entirely in recorded retrieval percentages. A consistently high cache hit rate indicates that the system successfully identifies and delivers stored data instead of computing fresh, resource-heavy answers. Over time, as the system processes more user requests, the internal database of recognized queries expands significantly.
Early testing environments often report moderate initial success metrics. As the application matures within the corporate network, intelligent semantic similarity mapping actively groups related questions together. This advanced deduplication process drives the system hit rate noticeably higher. In well-optimized enterprise deployments, these precise hit rates frequently peak at 94%, according to a 2026 operational survey. This high percentage translates directly to measurable LLM infrastructure savings.
System administrators must monitor these semantic hit rates continuously. Slight variations in prompt design sometimes generate entirely new processing demands. Using exact similarity hashing algorithms forces the active server to recognize slight spelling derivations as identical requests. Refining these technical matching protocols ultimately guarantees that memory efficiency remains incredibly high.
Concrete market evidence repeatedly highlights the extensive value of tokenized billing reductions. A global financial software provider deployed specific vendor-neutral memory logic on their custom reporting tools. By prioritizing intense prompt caching savings directly, they successfully reduced monthly generative AI expenditure from $36,000 to just $3,200 within a single business quarter.
Similarly, a leading healthcare diagnostics platform integrated advanced token-level memory optimization across their core patient analysis interface. This technical intervention produced an 89% immediate cost reduction while simultaneously doubling platform response speed. When central systems perform faster and consume fewer technical resources, organizations scale their complex workloads confidently. These reliable AI usage optimization patterns thoroughly redefine modern enterprise software expectations.
Detailed analysis of successful implementations reveals a consistent pattern of iterative architectural refinement. Technical teams iteratively analyze failure logs to determine exactly why specific requests bypass the existing cache. By adjusting similarity parameters based on this data, engineering groups secure total LLM total cost of ownership visibility.
While implementing advanced memory architecture optimizes the technical execution layer, tracking the financial impact requires deep integration across the broader software landscape. Establishing complete financial accountability guarantees that detailed token reduction efforts align properly with corporate operational directives. CloudNuro delivers actionable governance and centralized visibility across this exact enterprise landscape.

By utilizing AI Custodian, teams gain centralized, secure visibility into workload usage. The platform accurately measures cache savings, tracks exact hit rates, and directly correlates prompt reuse to specific billing metrics. The Unified Cloud Custodian automatically enforces rigorous cost optimization policies across various complex environments.
Additionally, sophisticated features like CloudNuro Chargeback allow finance departments to allocate specific artificial intelligence expenditures accurately. This robust governance-first architecture provides deep FinOps services that bring absolute transparency to modern technology stacks. Using a centralized methodology simplifies tracking SaaS management standards and ensures maximum investment utility.
It stores previously computed responses to standard corporate inputs. When comparable user requests arrive subsequently, the system serves the archived result instead of initiating a computationally expensive processing query entirely. This precise operation prevents duplicate API charges completely.
Organizations must urgently establish an architecture-agnostic layer that functions optimally across multiple cloud providers. Using advanced semantic deduplication guarantees that similar text inputs trigger the correct stored machine response. Regular usage strategy evaluations ensure these memory layers operate securely.
Corporate finance groups evaluate success by tracking total inference expenditures before and after technical deployment. Advanced centralized reporting dashboards monitor specific hit percentages and directly correlate those distinct metrics to exact departmental expenditures.
Refining the raw text queries systematically guarantees that hosted models only process necessary contextual data. According to industry researchers, this structural communication efficiency provides up to a 20% additional overall reduction in pure serving expenses when carefully paired with memory retrieval systems.
These structural deployment strategies function entirely independently of specific artificial intelligence developers. By utilizing an agnostic technical framework, modern technology leaders avoid negative cloud lock-in and apply uniform IT operations security standards across all internal generative services.
Achieving robust LLM cost reduction with caching changes the fundamental unit economics of enterprise artificial intelligence deployments. By preventing redundant processing operations, maintaining absolute vendor neutrality, and enforcing strict internal governance protocols, technology leaders reclaim vast portions of their allocated cloud budgets. Implementing sophisticated memory retrieval architectures protects valuable operational margins while simultaneously accelerating core application availability metrics.
Take definitive, calculated action to streamline expensive artificial intelligence expenditures. Review your current active model usage statistics thoroughly and deploy comprehensive architectural governance immediately. Complete internal financial transparency remains absolutely essential for sustained corporate growth. Focus distinctly on structured diagnostic data analysis to drive lasting, measurable operational profitability.
CloudNuro is a leader in Enterprise SaaS Management Platforms, providing enterprises with unmatched visibility, governance, and cost optimization. Recognized twice in a row in the SaaS Management Platforms category and named a Leader in the SoftwareReviews Data Quadrant, CloudNuro is trusted by global enterprises and government agencies to bring financial discipline to SaaS, cloud, and AI. Trusted by enterprises such as Konica Minolta and Federal Signal, CloudNuro provides centralized SaaS inventory, license optimization, and renewal management along with advanced cost allocation and chargeback, giving IT and Finance leaders the visibility, control, and cost-conscious culture needed to drive financial discipline.
Request a no cost, no obligation free assessment —just 15 minutes to savings!
Get StartedThe integration of generative artificial intelligence creates significant infrastructure challenges for modern engineering teams. Artificial intelligence implementation routinely brings unpredictable monthly operational expenses. Compute-intensive requests continuously drain available financial resources. However, established engineering groups find reliable enterprise AI cost governance through optimized token logic. By structuring model requests efficiently, technology departments achieve substantive LLM cost reduction with caching.
When user queries hit a complex language model repeatedly, computing the identical output squanders expensive cloud allocations. Standardizing request storage permanently prevents this duplicate processing. This specific systematic approach bypasses redundant generation entirely. Implementing pure, architecture-agnostic logic provides consistent financial returns for advanced generative AI products. This technical guide details a vendor-neutral playbook designed specifically to establish durable memory layers and protect valuable AI budgets.
Running vast language models requires astronomical computational power across server clusters. Every single generated sentence consumes specific processing units within the hosting environment. As internal application usage scales among diverse employee groups, these incremental processing requests compound rapidly. Gartner research from 2026 reveals that 50% of top enterprise organizations cite AI workload cost optimization as their primary operational challenge during initial adoption phases. Unchecked token generation swiftly forces cloud budgets toward critical threshold warnings.
Unmanaged diagnostic and conversational API bills frequently escalate without sufficient warning. A 2026 cost optimization benchmark survey reported that deploying active prompt caching structures decreased average API expenditures from $100,000 per month to under $10,000 per month. Optimizing these intricate systems represents a massive step toward long-term corporate AI sustainability. A targeted generative AI cost control mechanism guarantees that artificial intelligence deployment remains distinctly profitable over extended operating periods.
Furthermore, elastic AI workload scaling creates fluctuating demand that complicates standard budget forecasting. Organizations require predictable recurring expenses to justify continued engineering investment. By analyzing precise tokenized AI billing statements, finance teams identify major discrepancies between projected usage and actual technical consumption. Addressing these exact discrepancies forms the foundation for reliable, resilient corporate infrastructure.
At its core, a caching architecture acts as an intelligent intermediary. It sits directly between the application user interface and the backend processing cluster. When a specific user input enters the active system, the custom memory layer checks historic reference logs for identical text matches. If an exact match exists, the technical architecture returns the stored result instantly.
This operational framework moves processing from raw compute-bound workloads to highly memory-optimized retrievals. Rather than waiting for a complete machine learning generation cycle, responsive applications deliver archived answers. This sophisticated AI caching technique directly slashes expensive model serving expenses. Industry specialists emphasize that architecture-agnostic layers guarantee these savings across multiple hosting environments, preventing detrimental vendor dependencies completely.
Establishing these systems requires careful coordination among platform architects. Engineering leaders must configure exact caching rules that determine the appropriate lifespan for stored data points. Complex technical responses might require frequent refreshing, while standard operational definitions remain perfectly static. Mapping these specific parameters allows corporate teams to extract maximum value from existing server deployments. Continuous optimization of the caching architecture establishes a permanent efficiency standard.
Token optimization via deliberate prompt engineering provides a secondary, yet equally vital, financial advantage. When combined with intelligent caching protocols, streamlined engineering yields an additional 15% to 20% reduction in serving costs, according to a 2026 Forrester report. Organizations seeking immediate financial accountability rely heavily on deploying these dual mechanisms simultaneously.
Financial decision-makers require absolute evidence of cost-effective LLM solutions before authorizing widespread internal deployment. Establishing positive return on investment happens with surprising speed when the designated caching layer operates correctly. According to a 2026 IDC study, 45% of organizations implementing these architectures achieve mathematically positive returns within the first three months of active usage. Proper AI prompt efficiency planning clearly converts previously wasted cloud computing allocations into tangible working capital.
These rapid financial returns validate the initial engineering investment necessary for deployment. Companies capture the LLM vendor cost saving metrics immediately upon activation. By carefully auditing API transmission loads, managers construct precise financial summaries that document complete transformation progress. Eliminating wasteful token generation allows technical teams to fund other critical platform enhancements.
The true definitive measure of optimization success lies entirely in recorded retrieval percentages. A consistently high cache hit rate indicates that the system successfully identifies and delivers stored data instead of computing fresh, resource-heavy answers. Over time, as the system processes more user requests, the internal database of recognized queries expands significantly.
Early testing environments often report moderate initial success metrics. As the application matures within the corporate network, intelligent semantic similarity mapping actively groups related questions together. This advanced deduplication process drives the system hit rate noticeably higher. In well-optimized enterprise deployments, these precise hit rates frequently peak at 94%, according to a 2026 operational survey. This high percentage translates directly to measurable LLM infrastructure savings.
System administrators must monitor these semantic hit rates continuously. Slight variations in prompt design sometimes generate entirely new processing demands. Using exact similarity hashing algorithms forces the active server to recognize slight spelling derivations as identical requests. Refining these technical matching protocols ultimately guarantees that memory efficiency remains incredibly high.
Concrete market evidence repeatedly highlights the extensive value of tokenized billing reductions. A global financial software provider deployed specific vendor-neutral memory logic on their custom reporting tools. By prioritizing intense prompt caching savings directly, they successfully reduced monthly generative AI expenditure from $36,000 to just $3,200 within a single business quarter.
Similarly, a leading healthcare diagnostics platform integrated advanced token-level memory optimization across their core patient analysis interface. This technical intervention produced an 89% immediate cost reduction while simultaneously doubling platform response speed. When central systems perform faster and consume fewer technical resources, organizations scale their complex workloads confidently. These reliable AI usage optimization patterns thoroughly redefine modern enterprise software expectations.
Detailed analysis of successful implementations reveals a consistent pattern of iterative architectural refinement. Technical teams iteratively analyze failure logs to determine exactly why specific requests bypass the existing cache. By adjusting similarity parameters based on this data, engineering groups secure total LLM total cost of ownership visibility.
While implementing advanced memory architecture optimizes the technical execution layer, tracking the financial impact requires deep integration across the broader software landscape. Establishing complete financial accountability guarantees that detailed token reduction efforts align properly with corporate operational directives. CloudNuro delivers actionable governance and centralized visibility across this exact enterprise landscape.
By utilizing AI Custodian, teams gain centralized, secure visibility into workload usage. The platform accurately measures cache savings, tracks exact hit rates, and directly correlates prompt reuse to specific billing metrics. The Unified Cloud Custodian automatically enforces rigorous cost optimization policies across various complex environments.
Additionally, sophisticated features like CloudNuro Chargeback allow finance departments to allocate specific artificial intelligence expenditures accurately. This robust governance-first architecture provides deep FinOps services that bring absolute transparency to modern technology stacks. Using a centralized methodology simplifies tracking SaaS management standards and ensures maximum investment utility.
It stores previously computed responses to standard corporate inputs. When comparable user requests arrive subsequently, the system serves the archived result instead of initiating a computationally expensive processing query entirely. This precise operation prevents duplicate API charges completely.
Organizations must urgently establish an architecture-agnostic layer that functions optimally across multiple cloud providers. Using advanced semantic deduplication guarantees that similar text inputs trigger the correct stored machine response. Regular usage strategy evaluations ensure these memory layers operate securely.
Corporate finance groups evaluate success by tracking total inference expenditures before and after technical deployment. Advanced centralized reporting dashboards monitor specific hit percentages and directly correlate those distinct metrics to exact departmental expenditures.
Refining the raw text queries systematically guarantees that hosted models only process necessary contextual data. According to industry researchers, this structural communication efficiency provides up to a 20% additional overall reduction in pure serving expenses when carefully paired with memory retrieval systems.
These structural deployment strategies function entirely independently of specific artificial intelligence developers. By utilizing an agnostic technical framework, modern technology leaders avoid negative cloud lock-in and apply uniform IT operations security standards across all internal generative services.
Achieving robust LLM cost reduction with caching changes the fundamental unit economics of enterprise artificial intelligence deployments. By preventing redundant processing operations, maintaining absolute vendor neutrality, and enforcing strict internal governance protocols, technology leaders reclaim vast portions of their allocated cloud budgets. Implementing sophisticated memory retrieval architectures protects valuable operational margins while simultaneously accelerating core application availability metrics.
Take definitive, calculated action to streamline expensive artificial intelligence expenditures. Review your current active model usage statistics thoroughly and deploy comprehensive architectural governance immediately. Complete internal financial transparency remains absolutely essential for sustained corporate growth. Focus distinctly on structured diagnostic data analysis to drive lasting, measurable operational profitability.
CloudNuro is a leader in Enterprise SaaS Management Platforms, providing enterprises with unmatched visibility, governance, and cost optimization. Recognized twice in a row in the SaaS Management Platforms category and named a Leader in the SoftwareReviews Data Quadrant, CloudNuro is trusted by global enterprises and government agencies to bring financial discipline to SaaS, cloud, and AI. Trusted by enterprises such as Konica Minolta and Federal Signal, CloudNuro provides centralized SaaS inventory, license optimization, and renewal management along with advanced cost allocation and chargeback, giving IT and Finance leaders the visibility, control, and cost-conscious culture needed to drive financial discipline.
Request a no cost, no obligation free assessment - just 15 minutes to savings!
Get StartedWe're offering complimentary ServiceNow license assessments to only 25 enterprises this quarter who want to unlock immediate savings without disrupting operations.
Get Free AssessmentGet Started



CloudNuro Corp
1755 Park St. Suite 207
Naperville, IL 60563
Phone : +1-630-277-9470
Email: info@cloudnuro.com





.webp)

Recognized Leader in SaaS Management Platforms by Info-Tech SoftwareReviews



