
Sign Up
What is best time for the call?

Most enterprise AI leaders know their LLM costs are too high, yet few have a systematic way to control them. Prompt caching is one of the simplest, highest ROI levers available, yet 95% of enterprise AI teams are not using it as of Q1 2026 (Forrester 2026).
According to IDC, enterprises that deploy prompt caching report up to 56% reduction in LLM token and API costs in the first 12 months (IDC 2026). Forrester estimates that prompt caching can help large enterprises avoid processing over a trillion unnecessary tokens annually in big GenAI deployments (Forrester 2026).
This article explains what prompt caching is, how it works, and how to design an enterprise prompt caching strategy that aligns with AI cost governance, security, and FinOps goals. We will also show how CloudNuro helps CIOs and platform teams operationalize prompt caching as part of broader AI cost optimization.
At its core, prompt caching is a design pattern where repeated or similar LLM prompts and their responses are stored so that subsequent calls can reuse the cached result instead of sending a full request to the model again.
You can think of it as LLM prompt caching for your AI stack: just as web caches avoid regenerating the same page for every user, prompt caches avoid re-running identical or near-identical LLM computations.
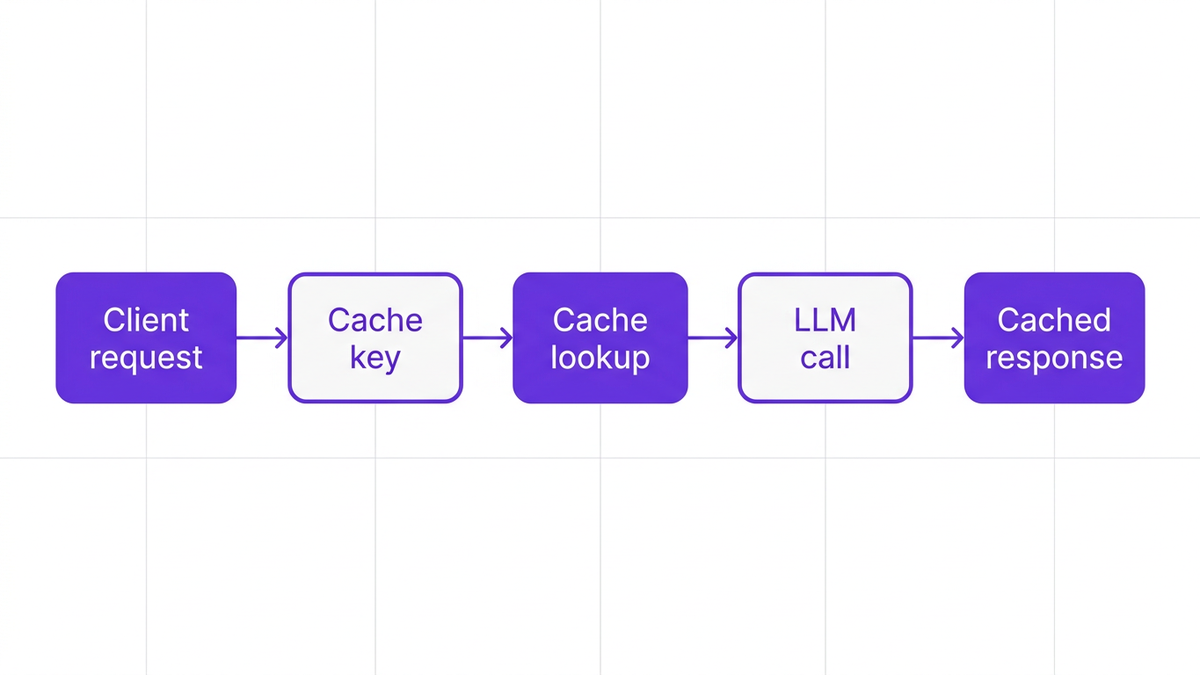
A typical prompt caching design pattern for enterprise AI looks like this:
Client request: An app or service sends a prompt (plus system instructions and context) to a prompt caching middleware.
Cache key generation: The middleware normalizes the request and generates a cache key based on the prompt, parameters, and sometimes user or tenant context.
Cache lookup: The system checks if the key exists in the prompt cache.
Cache hit: If found, it returns the stored response instantly and avoids a fresh LLM call.
Cache miss: If not found, it sends the prompt to the LLM provider, receives the response, stores it in the cache, then returns it to the client.
The result is a prompt caching middleware layer between your apps and LLM APIs that serves as a cost and performance control plane.
Different GenAI patterns benefit from prompt caching in different ways:
Static or semi-static prompts: Policy generation, compliance checks, template-based emails and standard operating procedures.
Repeated workflows: Customer support flows, standard approvals, onboarding sequences.
Multi-step chains: Complex chains where early steps (like classification or summarization) repeat across users.
In each of these, minimizing token waste in LLM apps comes from avoiding full recomputation for every nearly identical request.
The economic impact of prompt caching is not theoretical. Multiple research signals show it is becoming a foundational AI FinOps capability.
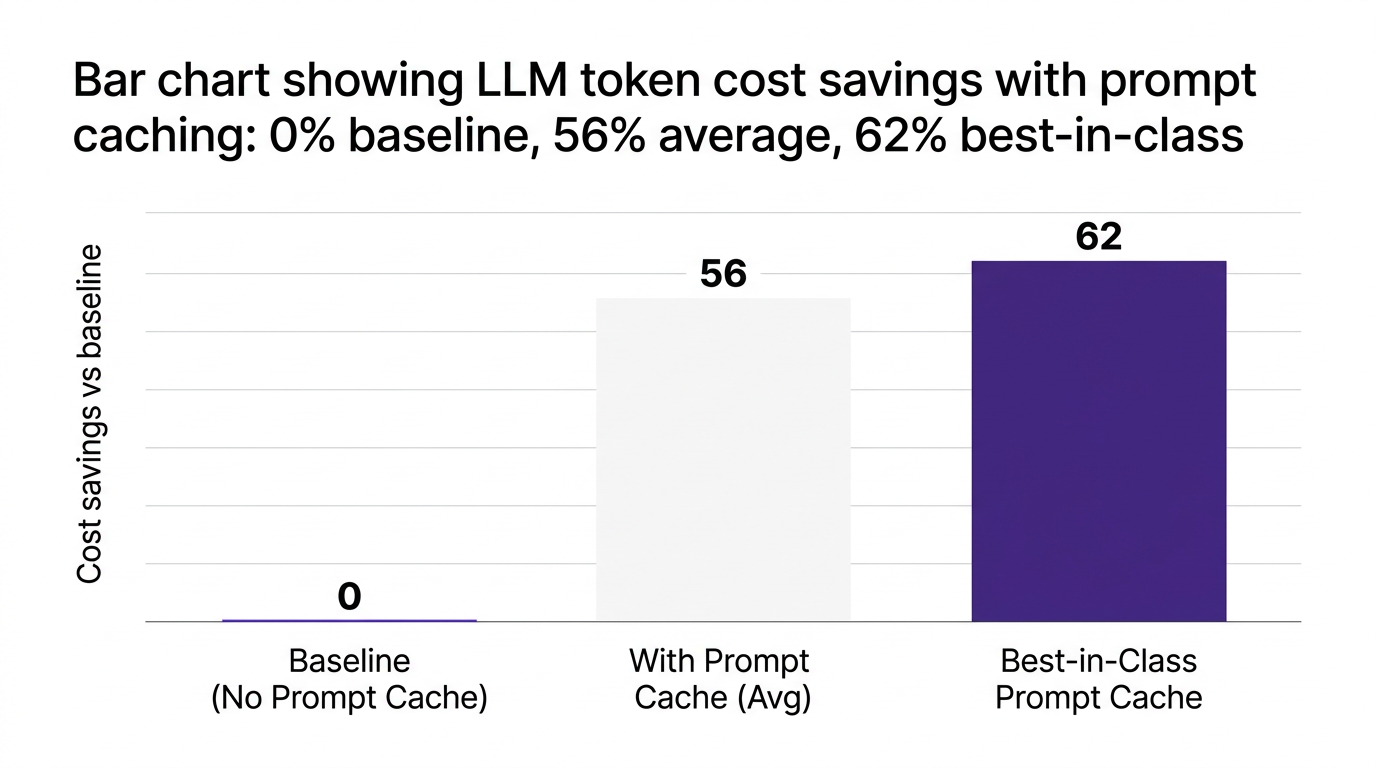
A 2026 IDC study found that enterprises deploying prompt caching achieved an average 56% reduction in LLM token and API costs within 12 months (IDC 2026). Best in class deployments reported savings above 60 percent.
Forrester estimates that prompt caching allows large enterprises to avoid over a trillion unnecessary tokens annually in mature GenAI portfolios (Forrester 2026). That reduction directly impacts LLM unit economics and GenAI ROI.
Despite these numbers, Forrester reports that 95% of enterprise AI teams do not yet use prompt caching as of Q1 2026.
Common reasons include:
Focus on model quality rather than LLM cost optimization.
Fragmented AI projects without shared infrastructure or an enterprise prompt caching solution.
Security and compliance concerns around storing prompts and responses.
Lack of ownership between platform engineering, security and FinOps teams.
This is similar to early cloud adoption where FinOps for enterprise AI was immature. Organizations rushed to build capabilities first, then discovered the bill.
Prompt caching is not only about costs. Research highlights 21 to 35% improvements in response times for enterprise AI deployments that use prompt caching (Gartner 2026).
This aligns with developer feedback that caching frequently used prompts reduces latency and improves user experience, especially for high-traffic internal tools or customer-facing assistants.
In other words, prompt caching behaves like a multi-tenant performance accelerator for LLM workloads.
Many teams ask: what is prompt caching compared to vector stores or traditional response caching? The distinctions matter for architecture and governance.
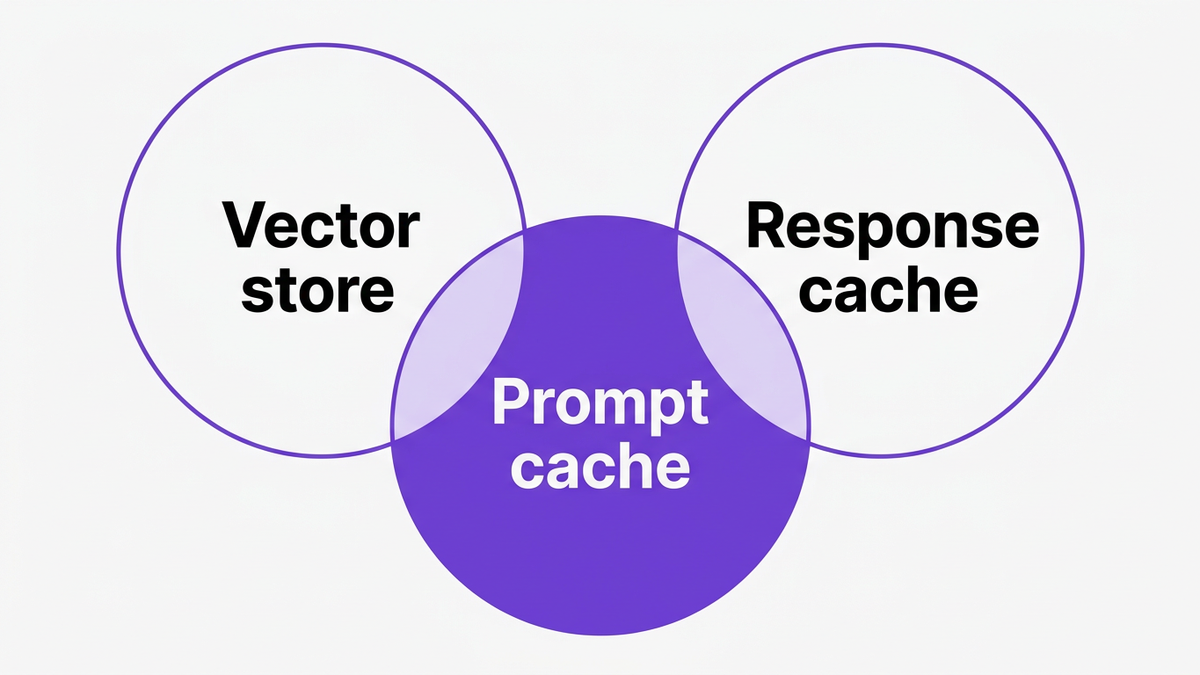
A vector store is typically used to retrieve relevant documents or embeddings based on semantic similarity, then those documents are used as context for the LLM.
By contrast, prompt caching focuses on caching the prompt plus response pair after the LLM has already processed it.
Key differences:
Vector stores retrieve context; prompt caches reuse completed responses.
Vector stores rely on similarity search, while prompt caches rely on exact or normalized prompt keys.
Vector stores help with relevance and grounding, while prompt caches help with LLM cost management and latency.
They are complementary, not competing. Many prompt caching architectures combine both.
Traditional response caching typically stores outputs based on URLs or request parameters.
Prompt caching is more nuanced because prompts can include:
System messages and roles.
Dynamic context, such as user metadata or retrieved documents.
Model configuration parameters.
An effective prompt caching platform must normalize all of this into a deterministic key and apply LLM-specific policies, such as:
Model version awareness.
Temperature and sampling settings.
Tenant or region boundaries.
In short, prompt caching vs response caching is less about terminology and more about LLM-aware caching logic.
Many teams first encounter prompt caching via prompt caching OpenAI examples or vendor documentation.
These often focus on basic cache layers close to the LLM provider. For enterprises, that is only the starting point. You also need:
Governance of what is cached and for how long.
Monitoring of cache hit ratios and token savings.
Integration with LLM FinOps and AI cost governance.
To tap the trillion-token opportunity, you need an enterprise prompt caching strategy that spans architecture, cost, governance, and security.

Start by mapping your GenAI estate:
Customer service assistants.
Internal knowledge tools.
Code assistants and dev tools.
Document processing or summarization pipelines.
Then prioritize workloads that are:
High volume and repetitive.
Latency sensitive.
Governed by consistent prompts or templates.
This is where cost optimization for LLM inference via caching yields the fastest returns.
An effective prompt caching design pattern depends on how you define cache keys.
Common strategies include:
Exact prompt hashing: Simple and reliable when prompts are deterministic.
Normalized prompts: Strip whitespace, ordering noise, or irrelevant parameters.
Template plus parameters: Separate the static instructions from dynamic inputs.
You may also incorporate tenant or region identifiers to enable multi-tenant prompt cache strategies without cross-tenant data exposure.
Not every prompt should live forever. You need time to live (TTL) and eviction rules aligned with business risk.
Examples:
Short TTLs for prompts that reference near real-time data.
Longer TTLs for stable policies, templates, or standard responses.
Priority-based eviction where critical workflows keep higher cache residency.
A good analogy is inventory management in a warehouse. Prompt caching decides which answers stay on the front shelf and which are recycled as demand changes.
Prompt caching cannot live only in engineering teams. It must be part of broader AI cost governance for enterprises.
Best practices include:
Defining ownership across platform engineering, security and FinOps.
Establishing KPIs such as token optimization for LLMs, cache hit rate and unit cost per request.
Integrating with enterprise GenAI cost optimization dashboards and monthly reviews.
This is where integrating with FinOps services pays off, since prompt caching directly feeds into overall AI spend and chargeback models.
Prompt caching is not a one-time setup. Over time, model changes, prompt patterns, and business usage evolve.
You need continuous LLM usage monitoring to catch:
Dropping cache hit rates.
New workloads bypassing the cache layer.
Security or compliance anomalies.
Treat prompt caching as a living control plane, not a static optimization trick.
CIOs and CISOs often ask whether prompt caching is secure and compliant in regulated industries.
A 2026 study found that CIOs in regulated sectors rank secure prompt caching as a top three requirement for AI infrastructure upgrades (InfoTech Research Group 2026). Another report found that 82% of organizations implementing prompt caching reported improved compliance visibility for GenAI apps (Everest Group 2026).

Enterprise prompt caching must be designed with security first.
Critical controls include:
Data classification: Decide which prompts and responses may be cached based on sensitivity.
Encryption at rest and in transit: Protect cached content with strong cryptography.
Role-based access control (RBAC): Limit who can access or manage caches.
Audit trails: Record which prompts were cached, accessed or purged.
These capabilities ensure AI cost optimization does not come at the expense of privacy or confidentiality.
MarketsandMarkets reports that regulated industries prioritize prompt cache solutions validated for SOC 2 and privacy controls in 2026.
Secure prompt caching can actually strengthen compliance since it:
Centralizes LLM interactions for better observation.
Enables audit-ready logs of AI requests and responses.
Supports data residency and regional control policies.
As one Everest Group expert notes, secure prompt caching architectures lower cost and simultaneously address critical compliance and audit needs (Everest Group 2026).
Some security teams argue that no prompts should be cached.
In practice, this is rarely necessary. You can:
Exclude specific fields or PII from cached payloads.
Cache only prompt templates and deterministic fragments.
Apply per-application policies with different cache rules.
This nuanced approach provides efficient prompt engineering for cost savings while respecting strict data policies.
Prompt caching has already delivered material savings in real enterprises.
A large financial institution cut its LLM API spend by 51% within nine months after deploying an enterprise prompt cache integrated with centralized FinOps reporting (Forrester 2026).

A healthcare network reduced AI inference costs by 47% while strengthening privacy controls by implementing a compliant prompt caching solution with audit-ready policies (Everest Group 2026).
These results align with broader market data:
The enterprise AI cost optimization software market, including prompt caching platforms, is projected to reach $5.7 billion by the end of 2026 (MarketsandMarkets 2026).
Enterprise adoption of prompt caching platforms is expected to double by the end of 2026, driven by board-level mandates to control GenAI spend (Gartner 2026).
There are scenarios where prompt caching does not deliver the expected results, typically due to design mistakes:
Highly dynamic prompts with unique content each time.
No shared infrastructure across teams, leading to siloed caches.
Lack of monitoring, so cache misses grow unnoticed.
In these cases, teams must revisit their prompt caching design pattern, refine cache keys and reconsider which workloads are suitable.
Prompt caching is powerful, but enterprises need governance-first architecture that embeds it in a broader AI and SaaS cost strategy.
CloudNuro’s AI Custodian module is designed exactly for this purpose.
CloudNuro integrates with major LLM providers to surface deep visibility into token utilization.
Using AI Custodian, teams can:
Track cache hits and misses for each GenAI application.
Identify where token optimization for LLMs is lagging.
Quantify savings from prompt caching by business unit or project.
These insights feed directly into FinOps-aligned reporting through CloudNuro’s unified dashboards and product overview.
CloudNuro’s architecture is built with governance-first principles.
For prompt caching, this translates into:
Role-based access for cache management.
Policy-driven decisions about what is cached, where, and for how long.
SOC 2 and privacy aligned controls suitable for sectors like healthcare and finance.
This means platform engineering, IT security and FinOps teams can collaborate in a single system rather than juggling ad hoc scripts or custom middleware.
Many enterprises run multiple GenAI apps on mixed cloud and SaaS stacks.
CloudNuro supports multi-tenant prompt cache patterns by:
Respecting tenant boundaries in cache keys.
Enforcing strict access segregation.
Aligning cache policies to IT operations and it asset management practices.
This is especially useful for shared platforms serving multiple business units or external agencies.
Prompt caching is only one lever in a broader AI cost optimization and SaaS governance program.
CloudNuro combines:
Centralized SaaS inventory and license optimization.
Unified cloud custodian capabilities for IaaS and PaaS costs.
AI-specific insights from AI Custodian.
By integrating prompt caching telemetry with FinOps services, enterprises can align GenAI spend with budgets, chargeback, and continuous optimization.
Prompt caching is the practice of storing LLM prompts and their responses so that repeated or similar requests do not require a new call to the model.
This reduces token consumption, cuts API costs and improves response times.
Every time an LLM call is avoided due to a cache hit, you avoid sending prompt tokens and receiving response tokens.
At scale, this reduction accumulates into large token savings and directly reduces LLM bills, making prompt caching one of the best ways to lower GenAI API spend.
Yes, if designed with security-first controls such as encryption, RBAC, data classification and audit logging.
Research shows that 82% of organizations implementing prompt caching report improved compliance visibility for GenAI applications (Everest Group 2026).
Vector stores retrieve relevant documents based on embeddings, while prompt caching stores full prompt plus response pairs.
They address different layers: vector stores help with relevance and grounding, while prompt caching focuses on LLM unit economics and latency.
IDC reports up to 56% reduction in LLM token and API costs within 12 months of deploying prompt caching (IDC 2026).
In large GenAI estates, Forrester estimates that prompt caching can avoid over a trillion unnecessary tokens per year, making it one of the highest ROI AI FinOps levers.
You can start with simple caching at the application layer.
However, enterprises with multiple AI workloads typically benefit from an enterprise prompt caching solution like CloudNuro’s AI Custodian that centralizes governance, monitoring and cost reporting.
Prompt caching is no longer an experimental optimization. It is becoming a foundational control in enterprise AI architectures, with tangible gains in LLM cost management, performance and compliance.
Most organizations are still in the 95 percent that have not systematized prompt caching. Those that move early can capture the trillion-token savings opportunity and embed AI FinOps discipline into their GenAI programs.
CloudNuro helps enterprises treat prompt caching not as a one-off trick, but as an integrated capability tied to SaaS governance, AI cost optimization and security.
To explore how prompt caching can reshape your AI economics:
CloudNuro is a leader in Enterprise SaaS Management Platforms, providing enterprises with unmatched visibility, governance, and cost optimization. Recognized twice in a row in the SaaS Management Platforms category and named a Leader in the SoftwareReviews Data Quadrant, CloudNuro is trusted by global enterprises and government agencies to bring financial discipline to SaaS, cloud, and AI.
Trusted by enterprises such as Konica Minolta and Federal Signal, CloudNuro provides centralized SaaS inventory, license optimization, and renewal management along with advanced cost allocation and chargeback, giving IT and Finance leaders the visibility, control, and cost-conscious culture needed to drive financial discipline.
Request a no cost, no obligation free assessment —just 15 minutes to savings!
Get StartedMost enterprise AI leaders know their LLM costs are too high, yet few have a systematic way to control them. Prompt caching is one of the simplest, highest ROI levers available, yet 95% of enterprise AI teams are not using it as of Q1 2026 (Forrester 2026).
According to IDC, enterprises that deploy prompt caching report up to 56% reduction in LLM token and API costs in the first 12 months (IDC 2026). Forrester estimates that prompt caching can help large enterprises avoid processing over a trillion unnecessary tokens annually in big GenAI deployments (Forrester 2026).
This article explains what prompt caching is, how it works, and how to design an enterprise prompt caching strategy that aligns with AI cost governance, security, and FinOps goals. We will also show how CloudNuro helps CIOs and platform teams operationalize prompt caching as part of broader AI cost optimization.
At its core, prompt caching is a design pattern where repeated or similar LLM prompts and their responses are stored so that subsequent calls can reuse the cached result instead of sending a full request to the model again.
You can think of it as LLM prompt caching for your AI stack: just as web caches avoid regenerating the same page for every user, prompt caches avoid re-running identical or near-identical LLM computations.
A typical prompt caching design pattern for enterprise AI looks like this:
Client request: An app or service sends a prompt (plus system instructions and context) to a prompt caching middleware.
Cache key generation: The middleware normalizes the request and generates a cache key based on the prompt, parameters, and sometimes user or tenant context.
Cache lookup: The system checks if the key exists in the prompt cache.
Cache hit: If found, it returns the stored response instantly and avoids a fresh LLM call.
Cache miss: If not found, it sends the prompt to the LLM provider, receives the response, stores it in the cache, then returns it to the client.
The result is a prompt caching middleware layer between your apps and LLM APIs that serves as a cost and performance control plane.
Different GenAI patterns benefit from prompt caching in different ways:
Static or semi-static prompts: Policy generation, compliance checks, template-based emails and standard operating procedures.
Repeated workflows: Customer support flows, standard approvals, onboarding sequences.
Multi-step chains: Complex chains where early steps (like classification or summarization) repeat across users.
In each of these, minimizing token waste in LLM apps comes from avoiding full recomputation for every nearly identical request.
The economic impact of prompt caching is not theoretical. Multiple research signals show it is becoming a foundational AI FinOps capability.
A 2026 IDC study found that enterprises deploying prompt caching achieved an average 56% reduction in LLM token and API costs within 12 months (IDC 2026). Best in class deployments reported savings above 60 percent.
Forrester estimates that prompt caching allows large enterprises to avoid over a trillion unnecessary tokens annually in mature GenAI portfolios (Forrester 2026). That reduction directly impacts LLM unit economics and GenAI ROI.
Despite these numbers, Forrester reports that 95% of enterprise AI teams do not yet use prompt caching as of Q1 2026.
Common reasons include:
Focus on model quality rather than LLM cost optimization.
Fragmented AI projects without shared infrastructure or an enterprise prompt caching solution.
Security and compliance concerns around storing prompts and responses.
Lack of ownership between platform engineering, security and FinOps teams.
This is similar to early cloud adoption where FinOps for enterprise AI was immature. Organizations rushed to build capabilities first, then discovered the bill.
Prompt caching is not only about costs. Research highlights 21 to 35% improvements in response times for enterprise AI deployments that use prompt caching (Gartner 2026).
This aligns with developer feedback that caching frequently used prompts reduces latency and improves user experience, especially for high-traffic internal tools or customer-facing assistants.
In other words, prompt caching behaves like a multi-tenant performance accelerator for LLM workloads.
Many teams ask: what is prompt caching compared to vector stores or traditional response caching? The distinctions matter for architecture and governance.
A vector store is typically used to retrieve relevant documents or embeddings based on semantic similarity, then those documents are used as context for the LLM.
By contrast, prompt caching focuses on caching the prompt plus response pair after the LLM has already processed it.
Key differences:
Vector stores retrieve context; prompt caches reuse completed responses.
Vector stores rely on similarity search, while prompt caches rely on exact or normalized prompt keys.
Vector stores help with relevance and grounding, while prompt caches help with LLM cost management and latency.
They are complementary, not competing. Many prompt caching architectures combine both.
Traditional response caching typically stores outputs based on URLs or request parameters.
Prompt caching is more nuanced because prompts can include:
System messages and roles.
Dynamic context, such as user metadata or retrieved documents.
Model configuration parameters.
An effective prompt caching platform must normalize all of this into a deterministic key and apply LLM-specific policies, such as:
Model version awareness.
Temperature and sampling settings.
Tenant or region boundaries.
In short, prompt caching vs response caching is less about terminology and more about LLM-aware caching logic.
Many teams first encounter prompt caching via prompt caching OpenAI examples or vendor documentation.
These often focus on basic cache layers close to the LLM provider. For enterprises, that is only the starting point. You also need:
Governance of what is cached and for how long.
Monitoring of cache hit ratios and token savings.
Integration with LLM FinOps and AI cost governance.
To tap the trillion-token opportunity, you need an enterprise prompt caching strategy that spans architecture, cost, governance, and security.
Start by mapping your GenAI estate:
Customer service assistants.
Internal knowledge tools.
Code assistants and dev tools.
Document processing or summarization pipelines.
Then prioritize workloads that are:
High volume and repetitive.
Latency sensitive.
Governed by consistent prompts or templates.
This is where cost optimization for LLM inference via caching yields the fastest returns.
An effective prompt caching design pattern depends on how you define cache keys.
Common strategies include:
Exact prompt hashing: Simple and reliable when prompts are deterministic.
Normalized prompts: Strip whitespace, ordering noise, or irrelevant parameters.
Template plus parameters: Separate the static instructions from dynamic inputs.
You may also incorporate tenant or region identifiers to enable multi-tenant prompt cache strategies without cross-tenant data exposure.
Not every prompt should live forever. You need time to live (TTL) and eviction rules aligned with business risk.
Examples:
Short TTLs for prompts that reference near real-time data.
Longer TTLs for stable policies, templates, or standard responses.
Priority-based eviction where critical workflows keep higher cache residency.
A good analogy is inventory management in a warehouse. Prompt caching decides which answers stay on the front shelf and which are recycled as demand changes.
Prompt caching cannot live only in engineering teams. It must be part of broader AI cost governance for enterprises.
Best practices include:
Defining ownership across platform engineering, security and FinOps.
Establishing KPIs such as token optimization for LLMs, cache hit rate and unit cost per request.
Integrating with enterprise GenAI cost optimization dashboards and monthly reviews.
This is where integrating with FinOps services pays off, since prompt caching directly feeds into overall AI spend and chargeback models.
Prompt caching is not a one-time setup. Over time, model changes, prompt patterns, and business usage evolve.
You need continuous LLM usage monitoring to catch:
Dropping cache hit rates.
New workloads bypassing the cache layer.
Security or compliance anomalies.
Treat prompt caching as a living control plane, not a static optimization trick.
CIOs and CISOs often ask whether prompt caching is secure and compliant in regulated industries.
A 2026 study found that CIOs in regulated sectors rank secure prompt caching as a top three requirement for AI infrastructure upgrades (InfoTech Research Group 2026). Another report found that 82% of organizations implementing prompt caching reported improved compliance visibility for GenAI apps (Everest Group 2026).
Enterprise prompt caching must be designed with security first.
Critical controls include:
Data classification: Decide which prompts and responses may be cached based on sensitivity.
Encryption at rest and in transit: Protect cached content with strong cryptography.
Role-based access control (RBAC): Limit who can access or manage caches.
Audit trails: Record which prompts were cached, accessed or purged.
These capabilities ensure AI cost optimization does not come at the expense of privacy or confidentiality.
MarketsandMarkets reports that regulated industries prioritize prompt cache solutions validated for SOC 2 and privacy controls in 2026.
Secure prompt caching can actually strengthen compliance since it:
Centralizes LLM interactions for better observation.
Enables audit-ready logs of AI requests and responses.
Supports data residency and regional control policies.
As one Everest Group expert notes, secure prompt caching architectures lower cost and simultaneously address critical compliance and audit needs (Everest Group 2026).
Some security teams argue that no prompts should be cached.
In practice, this is rarely necessary. You can:
Exclude specific fields or PII from cached payloads.
Cache only prompt templates and deterministic fragments.
Apply per-application policies with different cache rules.
This nuanced approach provides efficient prompt engineering for cost savings while respecting strict data policies.
Prompt caching has already delivered material savings in real enterprises.
A large financial institution cut its LLM API spend by 51% within nine months after deploying an enterprise prompt cache integrated with centralized FinOps reporting (Forrester 2026).
A healthcare network reduced AI inference costs by 47% while strengthening privacy controls by implementing a compliant prompt caching solution with audit-ready policies (Everest Group 2026).
These results align with broader market data:
The enterprise AI cost optimization software market, including prompt caching platforms, is projected to reach $5.7 billion by the end of 2026 (MarketsandMarkets 2026).
Enterprise adoption of prompt caching platforms is expected to double by the end of 2026, driven by board-level mandates to control GenAI spend (Gartner 2026).
There are scenarios where prompt caching does not deliver the expected results, typically due to design mistakes:
Highly dynamic prompts with unique content each time.
No shared infrastructure across teams, leading to siloed caches.
Lack of monitoring, so cache misses grow unnoticed.
In these cases, teams must revisit their prompt caching design pattern, refine cache keys and reconsider which workloads are suitable.
Prompt caching is powerful, but enterprises need governance-first architecture that embeds it in a broader AI and SaaS cost strategy.
CloudNuro’s AI Custodian module is designed exactly for this purpose.
CloudNuro integrates with major LLM providers to surface deep visibility into token utilization.
Using AI Custodian, teams can:
Track cache hits and misses for each GenAI application.
Identify where token optimization for LLMs is lagging.
Quantify savings from prompt caching by business unit or project.
These insights feed directly into FinOps-aligned reporting through CloudNuro’s unified dashboards and product overview.
CloudNuro’s architecture is built with governance-first principles.
For prompt caching, this translates into:
Role-based access for cache management.
Policy-driven decisions about what is cached, where, and for how long.
SOC 2 and privacy aligned controls suitable for sectors like healthcare and finance.
This means platform engineering, IT security and FinOps teams can collaborate in a single system rather than juggling ad hoc scripts or custom middleware.
Many enterprises run multiple GenAI apps on mixed cloud and SaaS stacks.
CloudNuro supports multi-tenant prompt cache patterns by:
Respecting tenant boundaries in cache keys.
Enforcing strict access segregation.
Aligning cache policies to IT operations and it asset management practices.
This is especially useful for shared platforms serving multiple business units or external agencies.
Prompt caching is only one lever in a broader AI cost optimization and SaaS governance program.
CloudNuro combines:
Centralized SaaS inventory and license optimization.
Unified cloud custodian capabilities for IaaS and PaaS costs.
AI-specific insights from AI Custodian.
By integrating prompt caching telemetry with FinOps services, enterprises can align GenAI spend with budgets, chargeback, and continuous optimization.
Prompt caching is the practice of storing LLM prompts and their responses so that repeated or similar requests do not require a new call to the model.
This reduces token consumption, cuts API costs and improves response times.
Every time an LLM call is avoided due to a cache hit, you avoid sending prompt tokens and receiving response tokens.
At scale, this reduction accumulates into large token savings and directly reduces LLM bills, making prompt caching one of the best ways to lower GenAI API spend.
Yes, if designed with security-first controls such as encryption, RBAC, data classification and audit logging.
Research shows that 82% of organizations implementing prompt caching report improved compliance visibility for GenAI applications (Everest Group 2026).
Vector stores retrieve relevant documents based on embeddings, while prompt caching stores full prompt plus response pairs.
They address different layers: vector stores help with relevance and grounding, while prompt caching focuses on LLM unit economics and latency.
IDC reports up to 56% reduction in LLM token and API costs within 12 months of deploying prompt caching (IDC 2026).
In large GenAI estates, Forrester estimates that prompt caching can avoid over a trillion unnecessary tokens per year, making it one of the highest ROI AI FinOps levers.
You can start with simple caching at the application layer.
However, enterprises with multiple AI workloads typically benefit from an enterprise prompt caching solution like CloudNuro’s AI Custodian that centralizes governance, monitoring and cost reporting.
Prompt caching is no longer an experimental optimization. It is becoming a foundational control in enterprise AI architectures, with tangible gains in LLM cost management, performance and compliance.
Most organizations are still in the 95 percent that have not systematized prompt caching. Those that move early can capture the trillion-token savings opportunity and embed AI FinOps discipline into their GenAI programs.
CloudNuro helps enterprises treat prompt caching not as a one-off trick, but as an integrated capability tied to SaaS governance, AI cost optimization and security.
To explore how prompt caching can reshape your AI economics:
CloudNuro is a leader in Enterprise SaaS Management Platforms, providing enterprises with unmatched visibility, governance, and cost optimization. Recognized twice in a row in the SaaS Management Platforms category and named a Leader in the SoftwareReviews Data Quadrant, CloudNuro is trusted by global enterprises and government agencies to bring financial discipline to SaaS, cloud, and AI.
Trusted by enterprises such as Konica Minolta and Federal Signal, CloudNuro provides centralized SaaS inventory, license optimization, and renewal management along with advanced cost allocation and chargeback, giving IT and Finance leaders the visibility, control, and cost-conscious culture needed to drive financial discipline.
Request a no cost, no obligation free assessment - just 15 minutes to savings!
Get StartedWe're offering complimentary ServiceNow license assessments to only 25 enterprises this quarter who want to unlock immediate savings without disrupting operations.
Get Free AssessmentGet Started



CloudNuro Corp
1755 Park St. Suite 207
Naperville, IL 60563
Phone : +1-630-277-9470
Email: info@cloudnuro.com





.webp)

Recognized Leader in SaaS Management Platforms by Info-Tech SoftwareReviews



