
Sign Up
What is best time for the call?

Enterprise teams rolling out large language model applications are discovering a hard truth: model quality alone does not control cost, latency, or compliance risk. How you cache LLM work is rapidly becoming as strategic as which model you choose, and the KV cache is at the center of that conversation.
A 2026 IDC study found that 71% of enterprises using advanced cache strategies, including semantic, prompt, and KV caching, reported a 38% reduction in operational costs. At the same time, Gartner reported that KV caching lowered LLM inference latency by 45% compared with prompt-only caching. The stakes are high for CIOs, CTOs, and IT operations leaders who must deliver AI at scale with financial discipline and strong governance.
This guide explains semantic caching, prompt caching, and KV cache in plain language, compares where each shines and fails, and shows how CloudNuro helps enterprises govern and optimize these caches across SaaS and cloud environments.
LLMs repeat themselves. The same tickets, emails, summaries, and policy checks are generated thousands of times a day across different departments and tools. Without caching, every one of those calls hits the model and the meter.
According to Deloitte in 2026, 82% of IT leaders in regulated industries cited security and compliance as their primary concern when deploying LLM cache solutions. At the same time, KPMG projects that FinOps enabled AI workload management, including intelligent caching, will save enterprises more than 2.7 billion dollars in SaaS and AI operational costs in 2026.
Why caching is now a board level topic:
Cost: Caching reduces repeat computation, which directly cuts token and infrastructure spend. McKinsey reported that prompt caching alone reduced duplicate LLM computation by 48% in large scale SaaS applications.
Performance: Gartner data shows KV caching delivers a 45% drop in latency, which drives better user satisfaction and business throughput.
Governance: Cached content can outlive source prompts. Without governance, you risk serving outdated, non compliant, or unapproved responses from cache.
Dr. Melissa Chang, Chief AI Architect at Gartner in 2026, summarized it clearly: “The selection of caching strategies directly impacts both LLM operational efficiency and enterprise governance; the right balance is crucial as AI integration deepens.”
Think of LLM caching as three different memory types in your AI stack. Each remembers something different and each has different tradeoffs for cost, latency, and control.
A prompt cache stores responses keyed by the exact prompt text, or a near exact representation. When the same prompt arrives again, the system returns the cached answer instead of asking the model again.
How prompt caching works in practice:
User sends a prompt, for example, “Summarize this incident ticket in 3 bullet points.”
System hashes the prompt and looks it up in the prompt cache.
If there is a hit, return the cached response. If not, query the model, then write the result into the cache.
Where prompt caching helps:
High volume, low variation tasks, such as recurring SaaS workflows or standardized emails.
Static content generation, for example policy snippets, knowledge base answers, or template outputs.
Environments where you want simple, deterministic reuse without complex similarity logic.
A McKinsey 2026 analysis found that prompt caching reduced duplicate LLM computations by 48% in large enterprise SaaS applications. For IT and procurement teams, this is equivalent to reclaiming nearly half of otherwise wasted AI spend on repeated work.
Limitations and risks:
Brittleness: A small change in wording, even with the same intent, often produces a miss.
Staleness: Without governance, cached responses can become outdated while still served as truth.
Limited context awareness: Prompt caches typically ignore deeper semantics and user context.
For many enterprises, prompt caching is a starting point, not an end state.
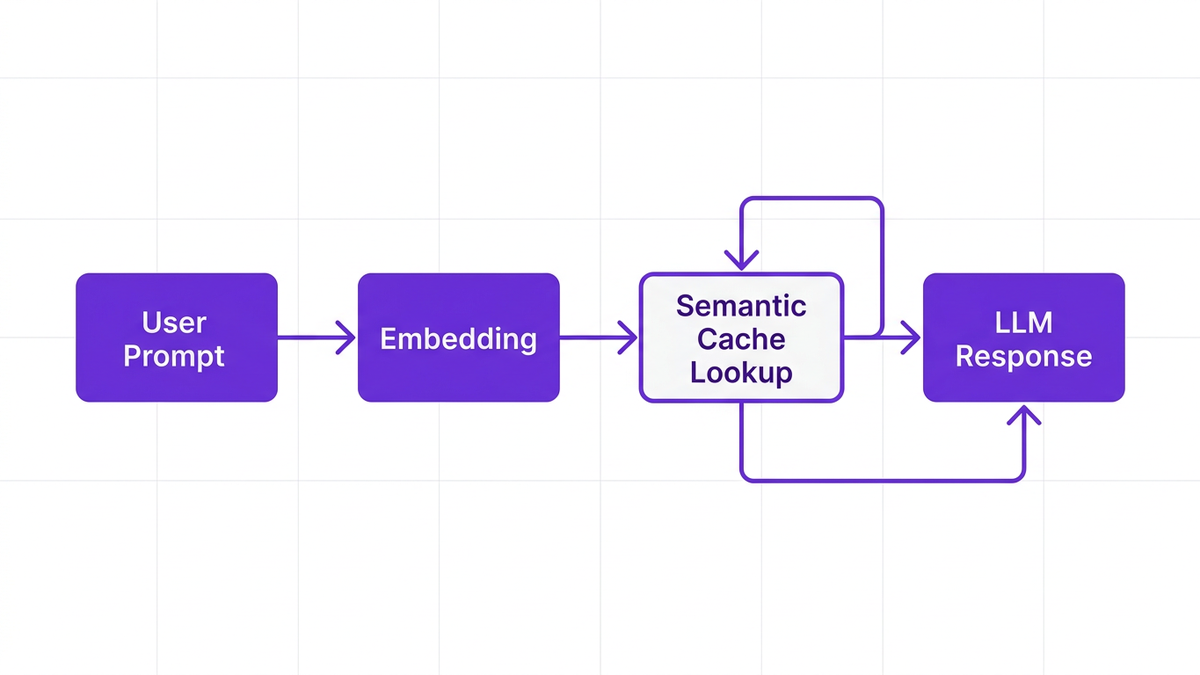
Semantic caching upgrades prompt caching by storing responses based on meaning rather than exact text. Instead of hashing raw prompts, the system encodes prompts into vector representations and compares new prompts to existing ones using similarity search.
How a semantic cache LLM pipeline works:
The incoming prompt is converted into an embedding vector.
The system queries a vector index to find similar past prompts.
If similarity exceeds a threshold, it returns the cached response, often after light validation.
If no suitable match is found, it calls the LLM and writes a new cache entry.
Forrester reported in 2026 that enterprises using semantic caching with governance frameworks saw a 34% improvement in AI application response consistency. That matters for scenarios like regulated policy explanations, benefits FAQs, or clinical trial protocol queries where consistency is critical.
Benefits for enterprises:
Higher hit rate than prompt cache: Captures similar intents phrased differently.
Improved user experience: More consistent responses, fewer surprises.
Great for knowledge heavy use cases: Support portals, internal policy assistants, and research tools.
Challenges to watch:
Similarity thresholds: Too high means misses and lost savings; too low risks serving semantically close but incorrect or non compliant answers.
Versioning and policy drift: When regulations or internal policies change, semantically cached responses may no longer be valid.
Data residency and privacy: Embeddings contain information about prompts, which may include sensitive or regulated data.
Priya Narayanan, LLM Optimization Lead cited by Forrester in 2026, notes: “Semantic caching, when paired with real time monitoring and policy controls, enables superior AI responsiveness for mission critical applications.” The qualifier matters; without governance, semantic caches can become a shadow knowledge base that no one owns.
The KV cache operates at a different layer. Instead of caching prompts or outputs, KV cache stores the model’s internal key and value representations for previous tokens, then reuses them in subsequent steps.
A simple analogy: prompt and semantic caches remember questions and answers, while the KV cache remembers partial calculations inside the brain that produced those answers.
What KV cache does in an LLM:
During token by token generation, the model computes attention over all previous tokens.
Those intermediate representations are expensive to recompute.
The KV cache stores them so that for each new token, the model reuses past states instead of recomputing from scratch.
Gartner’s 2026 research found that KV caching led to a 45% average decrease in LLM inference latency across enterprise deployments compared with prompt-only caching. For interactive experiences, that often makes the difference between “usable” and “abandoned.”
Key advantages of KV cache for LLM workloads:
Latency reduction: Faster token generation for long prompts, multi turn chats, and streaming responses.
Cost efficiency: Fewer compute cycles per request support lower infrastructure and cloud spending.
Scalability: Higher throughput with the same hardware footprint.
Where KV cache can struggle:
Long context limits: Large KV caches consume GPU or CPU memory; poor configuration can trigger out of memory incidents.
Multi tenant risk: If not isolated, KV segments could leak context across tenants.
Operational complexity: Tuning KV cache size, eviction strategies, and sharding strategies requires specialized expertise.
Rahul Mishra, Head of Cloud AI at Deloitte in 2026, argues that “KV caching is emerging as the enterprise standard for LLMs; its deterministic performance and robust compliance features align best with regulated industry needs.” For many teams, the question is not if they will use a KV cache LLM pattern, but how they will govern it.
To build an enterprise ready LLM cache strategy, you need to understand how these approaches intersect across cost, performance, and governance.
Use the CPR lens to assess each cache type:
Cost: How much compute and token spend does this cache type realistically avoid?
Performance: How much does it reduce latency and improve throughput?
Risk: What are the compliance, security, and correctness implications?
Prompt cache:
Cost: Good savings for identical or template driven work.
Performance: Moderate gains, especially for synchronous workflows.
Risk: Lower complexity but vulnerable to staleness and missing governance audit trails.
Semantic caching:
Cost: Strong savings for knowledge heavy apps with overlapping intent.
Performance: Good perceived speed due to higher hit rates.
Risk: Elevated if similarity thresholds and governance are weak; can serve incorrect but confident responses.
KV cache:
Cost: Strong infrastructure savings, especially on long sequences and streaming.
Performance: Excellent latency reduction; often mandatory for good user experience.
Risk: Technical rather than content centric; focuses on memory safety, multi tenant isolation, and observability.
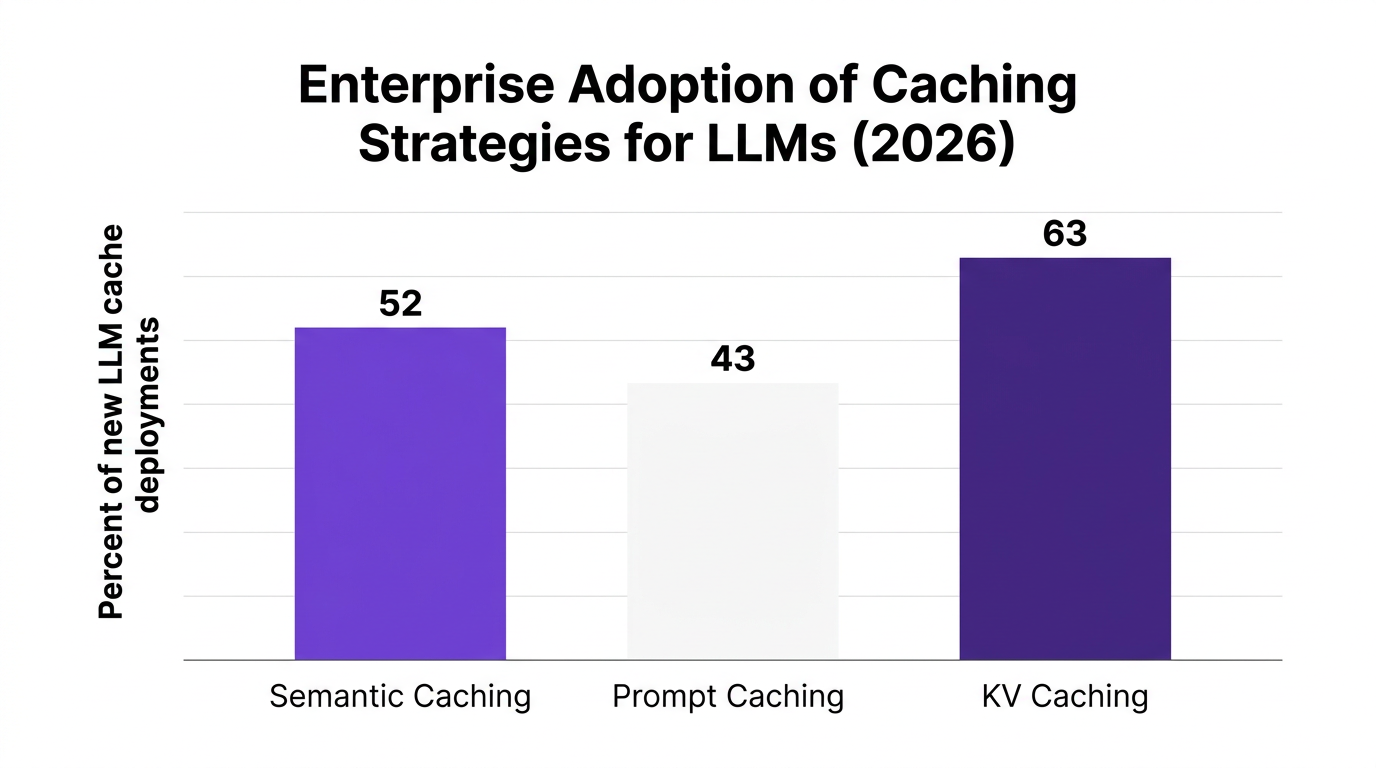
A Gartner 2026 forecast expects KV caching to account for 63% of new LLM cache deployments among large enterprises, with semantic caching adoption accelerating in healthcare and finance because of its impact on response consistency and auditability.
When this fails: two common anti patterns
Only prompt caching: Teams rely solely on prompt caching and ignore KV cache or semantic strategies. Result: limited savings, poor latency on long prompts, and frustrated users.
Un-governed semantic cache: Engineering implements semantic caching without compliance and IT involvement. Over time, the cache becomes a parallel, opaque knowledge store that no one reviews or controls.
Cloud and SaaS leaders should treat LLM caches as governed assets, not just performance optimizations.
82% of IT leaders in regulated sectors cite security and compliance as their top concern with LLM caching. The reason is simple: caches are data stores, and many were not originally designed with zero trust or regulatory scrutiny in mind.
For each cache type, IT, security, and compliance leaders should ask:
What data is stored, for how long, and under what encryption controls?
Can we segment caches by tenant, geography, and data classification?
Do we have audit trails for cache hits, misses, and overrides?
How are stale or policy violating responses detected and purged?
Semantic caches and prompt caches are especially sensitive because they may store or reconstruct regulated content. KV cache content is less interpretable but still carries risk if memory is not isolated and zeroized correctly.
A governance first approach to llm inference cache design should include:
Central visibility: Unified inventory of all semantic, prompt, and KV caches across SaaS and cloud.
Policy based retention: Time bound and condition bound retention rules based on data type and regulatory requirements.
Access control and segmentation: Role based access combined with tenant and environment scoping.
Real time monitoring: Alerts on unusual hit patterns, cross tenant access, or suspicious cache growth.
Change management: Workflows to invalidate or refresh caches when policies, prices, or regulations change.
A Deloitte 2026 survey found that 69% of enterprises are now making compliance monitoring a formal procurement requirement for cache frameworks that support AI workloads. This aligns with broader SaaS governance and cloud compliance solutions trends that SaaS leaders are already managing.

As enterprises roll out LLMs across Microsoft 365, CRM platforms, ITSM tools, and custom apps, the number of independent caches explodes. Different product teams may manage their own prompt caches, semantic caches, and KV cache llm stacks. Without centralized oversight, this quickly becomes a shadow IT problem.
CloudNuro’s governance first platform is built to bring that sprawl under control.
CloudNuro’s Unified Cloud Custodian and AI Custodian capabilities provide real time app discovery across SaaS, PaaS, and IaaS. As part of this, they can:
Discover where semantic caching, prompt caching, and KV caches are in use.
Map cache usage to specific business units, applications, and cost centers.
Identify unmanaged or unapproved LLM cache usage as part of broader SaaS sprawl management.
This gives IT and security teams a single pane of glass for LLM operational efficiency and risk.
CloudNuro’s Usage & Cost Optimization engine, combined with its FinOps services, helps enterprises turn caching data into actionable savings:
Analyze hit and miss rates for semantic, prompt, and KV caches.
Identify underused cache segments and misconfigured retention policies that drive unnecessary spend.
Correlate cache metrics with AI and SaaS invoices to support IT cost management and AI infrastructure savings.
This supports FinOps for AI, letting finance and IT leaders jointly decide where to invest in KV cache expansion, where to tighten semantic thresholds, and where to scale back caches that no longer provide value.
CloudNuro’s governance capabilities, reflected in its IT security solutions, extend directly to LLM cache governance:
Role based visibility into cache inventories and configurations.
Policy driven controls for retention, segmentation, and encryption.
Integration with security monitoring to flag anomalous cache behavior.
Alignment with broader SaaS management and cloud governance frameworks.
This governance-first design helps enterprises address security in LLM caching while staying aligned with SOC 2 Type II practices and sector specific compliance.
IT and AI leaders can start operationalizing an LLM cache strategy in five practical steps.
Use platforms like CloudNuro’s IT operations solution and SaaS management hub to:
Identify all applications that call LLMs today.
Classify them by criticality, data sensitivity, and regulatory exposure.
Document their current caching approaches, if any.
This inventory anchors both SaaS governance and LLM cache decisions.
Apply a simple mapping:
Prompt cache: Standardized templates, repeatable tickets, scripted responses, workflow automation SaaS actions.
Semantic caching: Knowledge retrieval, policy Q&A, research, and support contexts where questions vary but intent and source data are stable.
KV cache: Long prompts, high concurrency chat agents, streaming content, and any workload suffering from LLM latency reduction issues.
Most mature organizations will end up using all three, but with different weights depending on business priorities.
Collaborate with security, privacy, and compliance leaders to codify requirements for:
Data classification rules for cached content.
Encryption, access control, and segmentation standards.
Retention and purge policies aligned to regulations.
Monitoring and reporting expectations.
These become the guardrails against which any new semantic caching or kv cache llm deployment must be evaluated.
Caching is only successful if it contributes to measurable LLM cost optimization and SaaS cost optimization. Connect cache metrics to financial views:
Track cache enabled reduction in tokens, compute, and infrastructure spend.
Attribute savings to business units and applications using IT asset management style tagging with CloudNuro’s IT asset management solution.
Use benchmarks from IDC and KPMG research to validate whether you are in the 30 to 40 percent savings band that leading enterprises achieve.
Continue tuning by:
Adjusting semantic similarity thresholds to balance precision and savings.
Right sizing KV cache parameters to avoid memory pressure while preserving latency gains.
Regularly reviewing cache audit logs for anomalies and compliance issues.
Updating policies when regulations, internal risk appetite, or application usage patterns change.
Get a free assessment of how semantic, prompt, and KV cache could reduce your AI and SaaS spend
Semantic caching stores and retrieves LLM responses based on meaning, not exact text. It encodes prompts into embeddings, uses similarity search to find prior, semantically similar requests, and returns cached answers when the similarity passes a defined threshold.
For enterprises, semantic caching improves consistency and reduces compute for knowledge heavy scenarios, such as support portals and internal policy assistants. It must be governed carefully to avoid serving out of date or non compliant content.
Prompt caching operates at the application layer, storing full responses keyed by the prompt text or a normalized version of it. KV caching operates inside the model runtime, storing internal key and value states for tokens so the model avoids recomputing them on each new token.
Prompt caching improves cost and performance when prompts repeat exactly, while KV cache primarily improves latency and throughput for long prompts, multi turn chats, and streaming outputs. In practice, many enterprise LLM stacks use both.
LLM usage, like SaaS usage, tends to grow rapidly across business units, which drives up spend and performance expectations. Caching strategies allow enterprises to reduce redundant computation, control AI infrastructure costs, and deliver responsive experiences.
They also enable better governance by creating explicit places to apply policies, retention rules, and security controls around LLM data rather than leaving it embedded only in opaque logs or black box services.
The primary benefits of KV cache for LLM workloads are LLM latency reduction and improved scalability. By reusing internal attention states, KV cache allows long context interactions and streaming responses to run faster, which is vital for user facing agents and high throughput back end processes.
KV caching also drives AI infrastructure savings by reducing the per request compute work required, which, at scale, contributes directly to LLM cost optimization and better utilization of GPUs and CPUs.
No cache type is inherently secure without proper controls. Prompt and semantic caches are often more exposed to content related risks because they can store or reconstruct sensitive information. KV caches are more about internal model states, but still carry risks around memory isolation and multi tenant safety.
The most compliant strategy is one that treats all caches as governed data stores, with strong encryption, access controls, segmentation, retention policies, and monitoring. Platforms like CloudNuro help by providing centralized visibility and governance across all these cache layers.
Semantic caching, prompt caching, and the KV cache are no longer niche performance tricks. They are becoming core infrastructure for enterprise AI, touching cost, user experience, and regulatory exposure.
The most successful organizations will treat caches like any other critical asset: inventoried, governed, monitored, and optimized through a cloud optimization strategies and SaaS cost optimization lens. That means unifying LLM cache strategies, FinOps, and SaaS management under a common operating model.
CloudNuro helps enterprises do exactly this, unifying cache visibility, cost analytics, and governance controls across SaaS and cloud environments so AI initiatives are both high performing and financially disciplined.
CloudNuro is a leader in Enterprise SaaS Management Platforms, providing enterprises with unmatched visibility, governance, and cost optimization. Recognized twice in a row in the SaaS Management Platforms category and named a Leader in the SoftwareReviews Data Quadrant, CloudNuro is trusted by global enterprises and government agencies to bring financial discipline to SaaS, cloud, and AI.
Trusted by enterprises such as Konica Minolta and Federal Signal, CloudNuro provides centralized SaaS inventory, license optimization, and renewal management along with advanced cost allocation and chargeback, giving IT and Finance leaders the visibility, control, and cost conscious culture needed to drive financial discipline. Request a Demo | Get Free Savings | Explore Product Request a Demo -> https://www.cloudnuro.ai/request-demo
Get Free Savings -> https://www.cloudnuro.ai/free-savings-assessment
Explore Product -> https://www.cloudnuro.ai/product-overview
Request a no cost, no obligation free assessment —just 15 minutes to savings!
Get StartedEnterprise teams rolling out large language model applications are discovering a hard truth: model quality alone does not control cost, latency, or compliance risk. How you cache LLM work is rapidly becoming as strategic as which model you choose, and the KV cache is at the center of that conversation.
A 2026 IDC study found that 71% of enterprises using advanced cache strategies, including semantic, prompt, and KV caching, reported a 38% reduction in operational costs. At the same time, Gartner reported that KV caching lowered LLM inference latency by 45% compared with prompt-only caching. The stakes are high for CIOs, CTOs, and IT operations leaders who must deliver AI at scale with financial discipline and strong governance.
This guide explains semantic caching, prompt caching, and KV cache in plain language, compares where each shines and fails, and shows how CloudNuro helps enterprises govern and optimize these caches across SaaS and cloud environments.
LLMs repeat themselves. The same tickets, emails, summaries, and policy checks are generated thousands of times a day across different departments and tools. Without caching, every one of those calls hits the model and the meter.
According to Deloitte in 2026, 82% of IT leaders in regulated industries cited security and compliance as their primary concern when deploying LLM cache solutions. At the same time, KPMG projects that FinOps enabled AI workload management, including intelligent caching, will save enterprises more than 2.7 billion dollars in SaaS and AI operational costs in 2026.
Why caching is now a board level topic:
Cost: Caching reduces repeat computation, which directly cuts token and infrastructure spend. McKinsey reported that prompt caching alone reduced duplicate LLM computation by 48% in large scale SaaS applications.
Performance: Gartner data shows KV caching delivers a 45% drop in latency, which drives better user satisfaction and business throughput.
Governance: Cached content can outlive source prompts. Without governance, you risk serving outdated, non compliant, or unapproved responses from cache.
Dr. Melissa Chang, Chief AI Architect at Gartner in 2026, summarized it clearly: “The selection of caching strategies directly impacts both LLM operational efficiency and enterprise governance; the right balance is crucial as AI integration deepens.”
Think of LLM caching as three different memory types in your AI stack. Each remembers something different and each has different tradeoffs for cost, latency, and control.
A prompt cache stores responses keyed by the exact prompt text, or a near exact representation. When the same prompt arrives again, the system returns the cached answer instead of asking the model again.
How prompt caching works in practice:
User sends a prompt, for example, “Summarize this incident ticket in 3 bullet points.”
System hashes the prompt and looks it up in the prompt cache.
If there is a hit, return the cached response. If not, query the model, then write the result into the cache.
Where prompt caching helps:
High volume, low variation tasks, such as recurring SaaS workflows or standardized emails.
Static content generation, for example policy snippets, knowledge base answers, or template outputs.
Environments where you want simple, deterministic reuse without complex similarity logic.
A McKinsey 2026 analysis found that prompt caching reduced duplicate LLM computations by 48% in large enterprise SaaS applications. For IT and procurement teams, this is equivalent to reclaiming nearly half of otherwise wasted AI spend on repeated work.
Limitations and risks:
Brittleness: A small change in wording, even with the same intent, often produces a miss.
Staleness: Without governance, cached responses can become outdated while still served as truth.
Limited context awareness: Prompt caches typically ignore deeper semantics and user context.
For many enterprises, prompt caching is a starting point, not an end state.
Semantic caching upgrades prompt caching by storing responses based on meaning rather than exact text. Instead of hashing raw prompts, the system encodes prompts into vector representations and compares new prompts to existing ones using similarity search.
How a semantic cache LLM pipeline works:
The incoming prompt is converted into an embedding vector.
The system queries a vector index to find similar past prompts.
If similarity exceeds a threshold, it returns the cached response, often after light validation.
If no suitable match is found, it calls the LLM and writes a new cache entry.
Forrester reported in 2026 that enterprises using semantic caching with governance frameworks saw a 34% improvement in AI application response consistency. That matters for scenarios like regulated policy explanations, benefits FAQs, or clinical trial protocol queries where consistency is critical.
Benefits for enterprises:
Higher hit rate than prompt cache: Captures similar intents phrased differently.
Improved user experience: More consistent responses, fewer surprises.
Great for knowledge heavy use cases: Support portals, internal policy assistants, and research tools.
Challenges to watch:
Similarity thresholds: Too high means misses and lost savings; too low risks serving semantically close but incorrect or non compliant answers.
Versioning and policy drift: When regulations or internal policies change, semantically cached responses may no longer be valid.
Data residency and privacy: Embeddings contain information about prompts, which may include sensitive or regulated data.
Priya Narayanan, LLM Optimization Lead cited by Forrester in 2026, notes: “Semantic caching, when paired with real time monitoring and policy controls, enables superior AI responsiveness for mission critical applications.” The qualifier matters; without governance, semantic caches can become a shadow knowledge base that no one owns.
The KV cache operates at a different layer. Instead of caching prompts or outputs, KV cache stores the model’s internal key and value representations for previous tokens, then reuses them in subsequent steps.
A simple analogy: prompt and semantic caches remember questions and answers, while the KV cache remembers partial calculations inside the brain that produced those answers.
What KV cache does in an LLM:
During token by token generation, the model computes attention over all previous tokens.
Those intermediate representations are expensive to recompute.
The KV cache stores them so that for each new token, the model reuses past states instead of recomputing from scratch.
Gartner’s 2026 research found that KV caching led to a 45% average decrease in LLM inference latency across enterprise deployments compared with prompt-only caching. For interactive experiences, that often makes the difference between “usable” and “abandoned.”
Key advantages of KV cache for LLM workloads:
Latency reduction: Faster token generation for long prompts, multi turn chats, and streaming responses.
Cost efficiency: Fewer compute cycles per request support lower infrastructure and cloud spending.
Scalability: Higher throughput with the same hardware footprint.
Where KV cache can struggle:
Long context limits: Large KV caches consume GPU or CPU memory; poor configuration can trigger out of memory incidents.
Multi tenant risk: If not isolated, KV segments could leak context across tenants.
Operational complexity: Tuning KV cache size, eviction strategies, and sharding strategies requires specialized expertise.
Rahul Mishra, Head of Cloud AI at Deloitte in 2026, argues that “KV caching is emerging as the enterprise standard for LLMs; its deterministic performance and robust compliance features align best with regulated industry needs.” For many teams, the question is not if they will use a KV cache LLM pattern, but how they will govern it.
To build an enterprise ready LLM cache strategy, you need to understand how these approaches intersect across cost, performance, and governance.
Use the CPR lens to assess each cache type:
Cost: How much compute and token spend does this cache type realistically avoid?
Performance: How much does it reduce latency and improve throughput?
Risk: What are the compliance, security, and correctness implications?
Prompt cache:
Cost: Good savings for identical or template driven work.
Performance: Moderate gains, especially for synchronous workflows.
Risk: Lower complexity but vulnerable to staleness and missing governance audit trails.
Semantic caching:
Cost: Strong savings for knowledge heavy apps with overlapping intent.
Performance: Good perceived speed due to higher hit rates.
Risk: Elevated if similarity thresholds and governance are weak; can serve incorrect but confident responses.
KV cache:
Cost: Strong infrastructure savings, especially on long sequences and streaming.
Performance: Excellent latency reduction; often mandatory for good user experience.
Risk: Technical rather than content centric; focuses on memory safety, multi tenant isolation, and observability.
A Gartner 2026 forecast expects KV caching to account for 63% of new LLM cache deployments among large enterprises, with semantic caching adoption accelerating in healthcare and finance because of its impact on response consistency and auditability.
When this fails: two common anti patterns
Only prompt caching: Teams rely solely on prompt caching and ignore KV cache or semantic strategies. Result: limited savings, poor latency on long prompts, and frustrated users.
Un-governed semantic cache: Engineering implements semantic caching without compliance and IT involvement. Over time, the cache becomes a parallel, opaque knowledge store that no one reviews or controls.
Cloud and SaaS leaders should treat LLM caches as governed assets, not just performance optimizations.
82% of IT leaders in regulated sectors cite security and compliance as their top concern with LLM caching. The reason is simple: caches are data stores, and many were not originally designed with zero trust or regulatory scrutiny in mind.
For each cache type, IT, security, and compliance leaders should ask:
What data is stored, for how long, and under what encryption controls?
Can we segment caches by tenant, geography, and data classification?
Do we have audit trails for cache hits, misses, and overrides?
How are stale or policy violating responses detected and purged?
Semantic caches and prompt caches are especially sensitive because they may store or reconstruct regulated content. KV cache content is less interpretable but still carries risk if memory is not isolated and zeroized correctly.
A governance first approach to llm inference cache design should include:
Central visibility: Unified inventory of all semantic, prompt, and KV caches across SaaS and cloud.
Policy based retention: Time bound and condition bound retention rules based on data type and regulatory requirements.
Access control and segmentation: Role based access combined with tenant and environment scoping.
Real time monitoring: Alerts on unusual hit patterns, cross tenant access, or suspicious cache growth.
Change management: Workflows to invalidate or refresh caches when policies, prices, or regulations change.
A Deloitte 2026 survey found that 69% of enterprises are now making compliance monitoring a formal procurement requirement for cache frameworks that support AI workloads. This aligns with broader SaaS governance and cloud compliance solutions trends that SaaS leaders are already managing.
As enterprises roll out LLMs across Microsoft 365, CRM platforms, ITSM tools, and custom apps, the number of independent caches explodes. Different product teams may manage their own prompt caches, semantic caches, and KV cache llm stacks. Without centralized oversight, this quickly becomes a shadow IT problem.
CloudNuro’s governance first platform is built to bring that sprawl under control.
CloudNuro’s Unified Cloud Custodian and AI Custodian capabilities provide real time app discovery across SaaS, PaaS, and IaaS. As part of this, they can:
Discover where semantic caching, prompt caching, and KV caches are in use.
Map cache usage to specific business units, applications, and cost centers.
Identify unmanaged or unapproved LLM cache usage as part of broader SaaS sprawl management.
This gives IT and security teams a single pane of glass for LLM operational efficiency and risk.
CloudNuro’s Usage & Cost Optimization engine, combined with its FinOps services, helps enterprises turn caching data into actionable savings:
Analyze hit and miss rates for semantic, prompt, and KV caches.
Identify underused cache segments and misconfigured retention policies that drive unnecessary spend.
Correlate cache metrics with AI and SaaS invoices to support IT cost management and AI infrastructure savings.
This supports FinOps for AI, letting finance and IT leaders jointly decide where to invest in KV cache expansion, where to tighten semantic thresholds, and where to scale back caches that no longer provide value.
CloudNuro’s governance capabilities, reflected in its IT security solutions, extend directly to LLM cache governance:
Role based visibility into cache inventories and configurations.
Policy driven controls for retention, segmentation, and encryption.
Integration with security monitoring to flag anomalous cache behavior.
Alignment with broader SaaS management and cloud governance frameworks.
This governance-first design helps enterprises address security in LLM caching while staying aligned with SOC 2 Type II practices and sector specific compliance.
IT and AI leaders can start operationalizing an LLM cache strategy in five practical steps.
Use platforms like CloudNuro’s IT operations solution and SaaS management hub to:
Identify all applications that call LLMs today.
Classify them by criticality, data sensitivity, and regulatory exposure.
Document their current caching approaches, if any.
This inventory anchors both SaaS governance and LLM cache decisions.
Apply a simple mapping:
Prompt cache: Standardized templates, repeatable tickets, scripted responses, workflow automation SaaS actions.
Semantic caching: Knowledge retrieval, policy Q&A, research, and support contexts where questions vary but intent and source data are stable.
KV cache: Long prompts, high concurrency chat agents, streaming content, and any workload suffering from LLM latency reduction issues.
Most mature organizations will end up using all three, but with different weights depending on business priorities.
Collaborate with security, privacy, and compliance leaders to codify requirements for:
Data classification rules for cached content.
Encryption, access control, and segmentation standards.
Retention and purge policies aligned to regulations.
Monitoring and reporting expectations.
These become the guardrails against which any new semantic caching or kv cache llm deployment must be evaluated.
Caching is only successful if it contributes to measurable LLM cost optimization and SaaS cost optimization. Connect cache metrics to financial views:
Track cache enabled reduction in tokens, compute, and infrastructure spend.
Attribute savings to business units and applications using IT asset management style tagging with CloudNuro’s IT asset management solution.
Use benchmarks from IDC and KPMG research to validate whether you are in the 30 to 40 percent savings band that leading enterprises achieve.
Continue tuning by:
Adjusting semantic similarity thresholds to balance precision and savings.
Right sizing KV cache parameters to avoid memory pressure while preserving latency gains.
Regularly reviewing cache audit logs for anomalies and compliance issues.
Updating policies when regulations, internal risk appetite, or application usage patterns change.
Get a free assessment of how semantic, prompt, and KV cache could reduce your AI and SaaS spend
Semantic caching stores and retrieves LLM responses based on meaning, not exact text. It encodes prompts into embeddings, uses similarity search to find prior, semantically similar requests, and returns cached answers when the similarity passes a defined threshold.
For enterprises, semantic caching improves consistency and reduces compute for knowledge heavy scenarios, such as support portals and internal policy assistants. It must be governed carefully to avoid serving out of date or non compliant content.
Prompt caching operates at the application layer, storing full responses keyed by the prompt text or a normalized version of it. KV caching operates inside the model runtime, storing internal key and value states for tokens so the model avoids recomputing them on each new token.
Prompt caching improves cost and performance when prompts repeat exactly, while KV cache primarily improves latency and throughput for long prompts, multi turn chats, and streaming outputs. In practice, many enterprise LLM stacks use both.
LLM usage, like SaaS usage, tends to grow rapidly across business units, which drives up spend and performance expectations. Caching strategies allow enterprises to reduce redundant computation, control AI infrastructure costs, and deliver responsive experiences.
They also enable better governance by creating explicit places to apply policies, retention rules, and security controls around LLM data rather than leaving it embedded only in opaque logs or black box services.
The primary benefits of KV cache for LLM workloads are LLM latency reduction and improved scalability. By reusing internal attention states, KV cache allows long context interactions and streaming responses to run faster, which is vital for user facing agents and high throughput back end processes.
KV caching also drives AI infrastructure savings by reducing the per request compute work required, which, at scale, contributes directly to LLM cost optimization and better utilization of GPUs and CPUs.
No cache type is inherently secure without proper controls. Prompt and semantic caches are often more exposed to content related risks because they can store or reconstruct sensitive information. KV caches are more about internal model states, but still carry risks around memory isolation and multi tenant safety.
The most compliant strategy is one that treats all caches as governed data stores, with strong encryption, access controls, segmentation, retention policies, and monitoring. Platforms like CloudNuro help by providing centralized visibility and governance across all these cache layers.
Semantic caching, prompt caching, and the KV cache are no longer niche performance tricks. They are becoming core infrastructure for enterprise AI, touching cost, user experience, and regulatory exposure.
The most successful organizations will treat caches like any other critical asset: inventoried, governed, monitored, and optimized through a cloud optimization strategies and SaaS cost optimization lens. That means unifying LLM cache strategies, FinOps, and SaaS management under a common operating model.
CloudNuro helps enterprises do exactly this, unifying cache visibility, cost analytics, and governance controls across SaaS and cloud environments so AI initiatives are both high performing and financially disciplined.
CloudNuro is a leader in Enterprise SaaS Management Platforms, providing enterprises with unmatched visibility, governance, and cost optimization. Recognized twice in a row in the SaaS Management Platforms category and named a Leader in the SoftwareReviews Data Quadrant, CloudNuro is trusted by global enterprises and government agencies to bring financial discipline to SaaS, cloud, and AI.
Trusted by enterprises such as Konica Minolta and Federal Signal, CloudNuro provides centralized SaaS inventory, license optimization, and renewal management along with advanced cost allocation and chargeback, giving IT and Finance leaders the visibility, control, and cost conscious culture needed to drive financial discipline. Request a Demo | Get Free Savings | Explore Product Request a Demo -> https://www.cloudnuro.ai/request-demo
Get Free Savings -> https://www.cloudnuro.ai/free-savings-assessment
Explore Product -> https://www.cloudnuro.ai/product-overview
Request a no cost, no obligation free assessment - just 15 minutes to savings!
Get StartedWe're offering complimentary ServiceNow license assessments to only 25 enterprises this quarter who want to unlock immediate savings without disrupting operations.
Get Free AssessmentGet Started



CloudNuro Corp
1755 Park St. Suite 207
Naperville, IL 60563
Phone : +1-630-277-9470
Email: info@cloudnuro.com





.webp)

Recognized Leader in SaaS Management Platforms by Info-Tech SoftwareReviews



